Fun of Dissecting Paper
In this post, we will take a different approach to learn a topic. We will be looking at various papers in the topic of Learning to learn aka Meta-Learning but here we will provide a curriculum, starting with introduction to the meta-learning and then diving into specifics of different algorithms in meta-learning and finally implementing them.
All the codes implemented in Jupyter notebook in PyTorch – meta_learning_baseline, meta_learning_baseline++ and meta_learning_maml
All codes can be run on Google Colab (link provided in notebook).
Hey yo, but how?
Well sit tight and buckle up. I will go through everything in-detail.

Feel free to jump anywhere,
Ah, you must be wondering why is I-know-everything not present to teach the disciple I-know-nothing dissect the papers. Before leaving for a nice summer holiday, I-know-everything has outlined a different approach to learn a topic.
How to Learn Learning to Learn?
We will divide the task into a 3-week long learning journey. In the first week, we will focus on getting familiar with the term meta-learning and various terminologies associated with it. We will jump into 3 papers which explore meta-learning through metrics-based algorithms. In the following week, we will dive into some other types of learning algorithms namely model-based and optimization-based meta-learning algorithms and learn in-detail about them. In the third week, we will implement some of the algorithms we looked at in the previous week.
Week 1 (Getting Started)
Video & Slides
Video Introductory talk by Oriol Vinyals if in hurry jump to last 30 minutes and Slides
Video On Learning How to Learn Learning Strategies
Video Siamese Network and One Shot Learning
Blog
🐣 From zero to research — An introduction to Meta-learning
Meta-Learning: Learning to Learn Fast
Paper
Siamese Neural Networks for One-shot Image Recognition by Koch et al aka Siamese Neural Networks
Matching networks for one shot learning by Vinyals et al aka Matching Networks
Learning to compare: Relation network for few-shot learning by Sung et al aka Relation Networks
Questions
-
How is meta-learning different from supervised learning?
-
How is dataset for training and testing setup different from typical setting?
-
What does names like meta-training, meta-testing, support, query mean?
-
What does “Go beyond train from samples from a single distribution” mean in meta-learning?
Week 2 (Diving into specifics)
Video & Slides
Video MILA Talks Few-Shot Learning with Meta-Learning: Progress Made and Challenges Ahead - Hugo Larochelle and Slides
Video ICML 2019 Meta-Learning: From Few-Shot Learning to Rapid Reinforcement Learning
Video NeurIPS 2017 Panel discussion
Video ICML 2019 Meta-Learning: Challenges and Frontiers by Chelsea Finn
Slides Model-Agnostic Meta-Learning Universality, Inductive Bias, and Weak Supervision
Blog
Reptile: A Scalable Meta-Learning Algorithm
Paper
Optimization as a model for Few-Shot Learning by Ravi & Larochelle aka Meta-Learner LSTM
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks by Finn et al aka MAML
Prototypical Networks for Few-shot Learning aka ProtoNet
On First-Order Meta-Learning Algorithms aka Reptile
Book
Questions
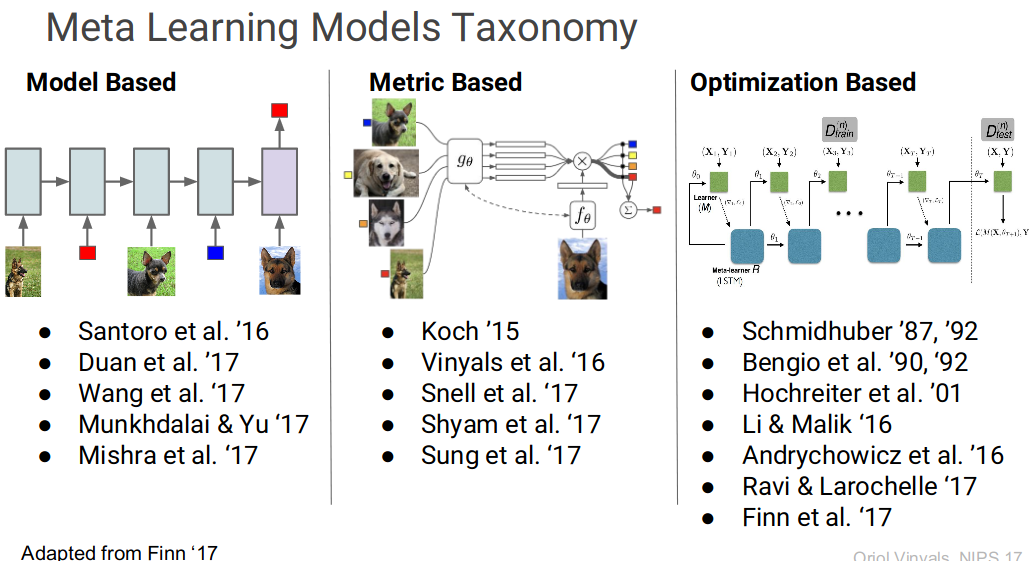
-
How is Meta-Learner LSTM different from Matching Networks?
-
How is MAML different from Meta-Learner LSTM?
Week 3 (Coding Challenge)
Video & Slides
Slides What’s Wrong with Meta-Learning(and how we might fix it)
Slides Meta-Learning Frontiers:Universal, Uncertain, and Unsupervised
Paper
Meta-Dataset: A Dataset of Datasets for Learning to Learn from Few Examples
A Closer Look at Few-shot Classification
Challenge
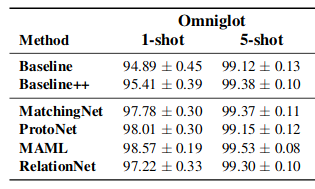
Challenge for this week will be to implement 3 algorithms from the paper A Closer Look at Few-shot Classification. We will implement baseline, baseline++ and MAML algorithms using Omniglot dataset and try to replicate the results shown in the paper.
Code
MAML
https://github.com/cbfinn/maml
https://github.com/dragen1860/MAML-Pytorch
https://github.com/katerakelly/pytorch-maml
https://github.com/AntreasAntoniou/HowToTrainYourMAMLPytorch
Prototypical Nets
https://github.com/jakesnell/prototypical-networks
Reptile
https://github.com/openai/supervised-reptile
Relational Nets
https://github.com/floodsung/LearningToCompare_FSL
4 Few-Shot Classification Algorithms
https://github.com/wyharveychen/CloserLookFewShot
Datasets
In next post, we will work on a project of building a text recognizer application.
Happy Learning!
Further Reading
NeurIPS 2017 Meta-learning symposium
NeurIPS 2017 Workshop on Meta-Learning
Learning to Optimize with Reinforcement Learning
Meta-Learning a Dynamical Language Model
Learning Unsupervised Learning Rules
Learning to learn by gradient descent by gradient descent
Footnotes and Credits
NOTE
Questions, comments, other feedback? E-mail the author