Series on Reinforcement Learning

Feel free to jump anywhere,
Reinforcement Learning
In Life 3.0, Max Tegmark explains how the origin of goal-oriented behaviour can be traced all the way back to laws of physics, which appear to endow particles with the goal of arranging themselves so as to extract energy from their environment as efficiently as possible. In a way, that is how life evolved, particular arrangement of particles getting so good at copying itself.
Sutton and Barto define reinforcement learning as a computational approach to understanding and automating goal-directed learning and decision making.
So how does reinforcement learning differ from supervised learning? In supervised learning, there will be a supervisor acting as a oracle judging whether you’re getting the right answer. In this type of learning, we are already presented with a data and it’s corresponding true label(ground truth). In reinforcement learning, there is no oracle dictating the actions an agent should take. The agent interacts with the environment, taking various actions and obtaining various rewards. The overall aim is to predict the best next step to take to earn the biggest final reward. After repeating this cycle of taking action and obtaining reward, we get a rough estimate of which state is good and bad. Both the supervised and reinforcement learning paradigms seem to require enormously more samples or trials than humans and animals to learn a new task.
In reinforcement learning system, agent interacts with the environment. At a time step \(t\), agent in a particular state \(s\) takes action \(a\). The environment takes in \(s\) and \(a\). The environment gives the agent a reward \(r\) and a new state \(s^{'}\). And the cycle repeats.
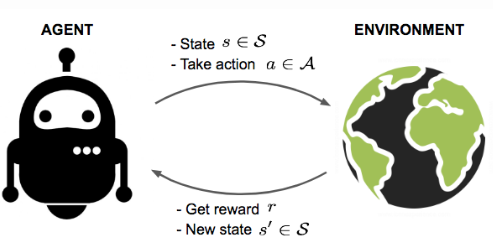
There are 4 main sub-elements of a reinforcement learning system:
- Policy
A policy is a mapping from perceived states of the environment to actions to be taken when in those states. It acts like a lookup table for a agent, directing it to take a particular action when in an particular state. Policies may be stochastic, i.e. specifying probabilities for each action. The policy is the core of a reinforcement learning agent in the sense that it alone is sufficient to determine behaviour. It is represented by symbol \(\pi\).
- Rewards
A reward signal defines the goal of a reinforcement learning problem. Agents can receive rewards either be received at the end of the episode or after taking each step. For example, a chess game will end in reward of +1(win), 0(draw) and -1(lose). Rewards acts as a feedback for agent and thus defines what are the good and bad events for the agent. Reward signals may be stochastic functions of the state of the environment and the actions taken. The agents sole objective is to maximise the total reward it receives over the long run. It is represented by symbol \(\mathcal{R}\).
- Value Function
The value of a state is the total amount of reward an agent can expect to accumulate over the future, starting from that state. It tells the agent how good it is to be in a particular state i.e. used to evaluate the goodness/badness of states. Based on this value functions, agents decides which actions should be selected. The difference between rewards and value function is rewards are given directly by environment but value function is estimated and re-estimated from the sequences of observation an agent makes over its entire lifetime. It is represented by symbol \(v_{\pi}(s)\), value of state \(s\) under policy \(\pi\).
- Model
A model is agent’s representation of the environment. A model predicts what the environment will do next. For example, given a state and action, the model might predict the resultant next state and next reward. Models are used for planning, i.e. deciding on a course of action by considering possible future situations before they are actually experienced. There are also model-free methods, where agents learns by trial-and-error as opposed to model-based methods, where an approximate model of environment is used for considering future situations.
Reinforcement Learning has its root in many fields such as psychology, neuroscience, economics, mathematics, engineering and computer science. One such example is, suppose the goal of the agent (human in this case) is to be happy. Agent will look for different ways, taking different actions from current state (policy) so as to change the mood to be in happy state. On changing state, the agent receives a reward (release of the neurotransmitter dopamine). “How happy the agent is” will be determined by the total reward received.
In subsequent posts, we will study in-depth two types of methods for solving reinforcement learning systems.
- Tabular Solution Methods
- Approximate Solution Methods
We will also use various environment like OpenAI Gym, PyGame Learning Environment and VizDoom. We will also implement RL algorithms in Deepdrive simulator, Atari games and maybe DuckieTown or any other.
Happy Learning!
Further Reading
Reinforcement Learning An Introduction 2nd edition : Chapter 1
UCL RL Course by David Silver : Lecture 1
Wildml Learning Reinforcement Learning
Machine Learning for Humans, Part 5: Reinforcement Learning
A Brief Survey of Deep Reinforcement Learning
UC Berkeley CS285 Deep Reinforcement Learning : Lecture 1
Footnotes and Credits
NOTE
Questions, comments, other feedback? E-mail the author