In this post, we will see if we can make use of Federated Learning to make our lives more private.
All the codes implemented in Jupyter notebook in Tensorflow and PyTorch + PySyft Library
All codes can be run on Google Colab (link provided in notebook).
Hey yo, but how?
Well sit tight and buckle up. I will go through everything in-detail.

Feel free to jump anywhere,
Federated Learning
In the wake of recent events related to privacy invasion through various methods of data collections by large corporations, it’s about time we think about alternatives ways of collecting data before more users become aware as to why are they getting such excellent vision, text prediction and recommendation systems based on their recent watch history. (Hint: by training on their data by invading their privacy, ringing any bells?) One such example is Detectron by Facebook trained on 3 billion images from Instagram. This is what McMahan and group must have thought (coming from Google itself, a bit ironic isn’t it?) and hence, they proposed a learning method of using decentralised data in this remarkable paper through decentralized approach termed as Federated Learning.
Traditional learning algorithms learns on mountain loads of data gathered from many different users which is stored in some central server. Then, distributed learning model is created and trained on mountain loads of user data for months and months. After training, they come back to user promising that they have made their app more intelligent (without hinting: with help of your data, so mean).
Federated Learning (FL) uses decentralized approach for training the model using the user (privacy-sensitive) data. In short, the traditional learning methods had approach of, “brining the data to code”, instead of “code to data”. FL is all about the latter approach.
How it Works?
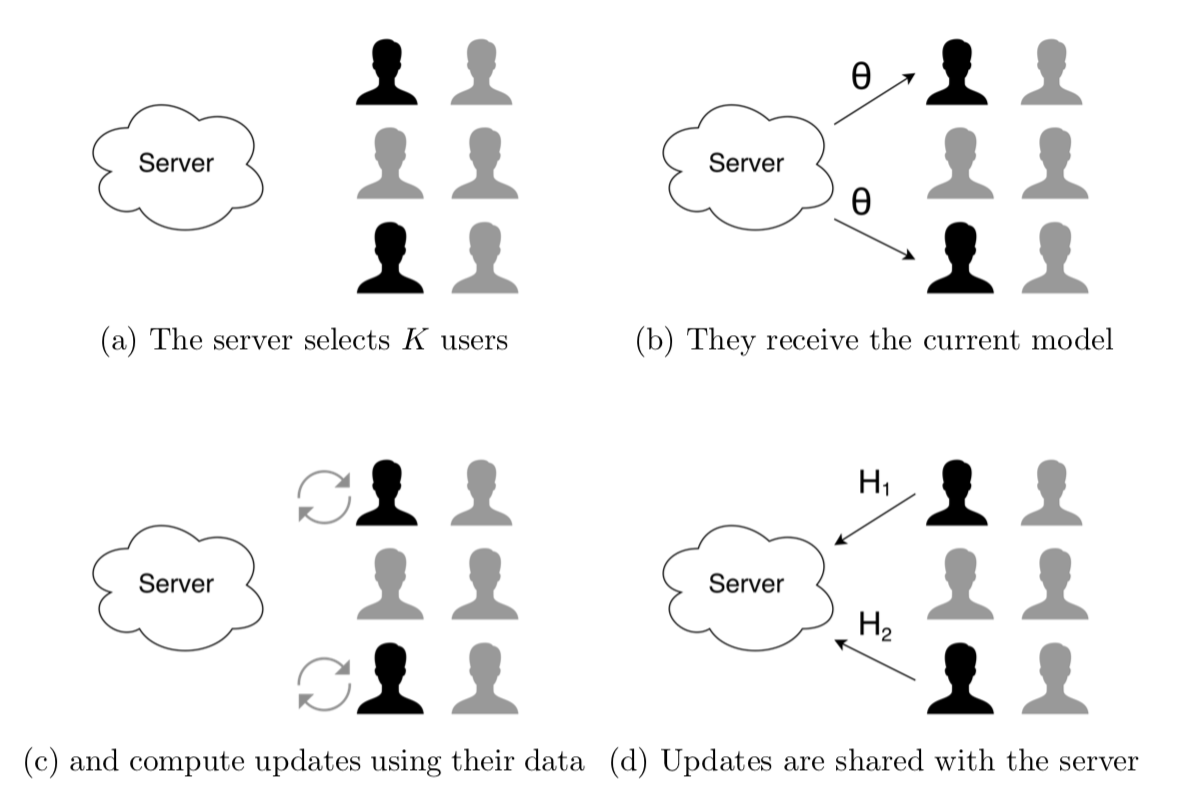
In series of rounds(of communication) server selectes K random users(clients) to participate in training. Each selected user downloads the current model from server and performs some number of local updates using its local training data (\(\mathbf{H}_{i}\)); for example it may perform single epoch of minibatch SGD. Then the users upload their model update – that is,the difference between the final parameters after training and the original parameters – and the server averages the contributions before accumulating them into the global model.
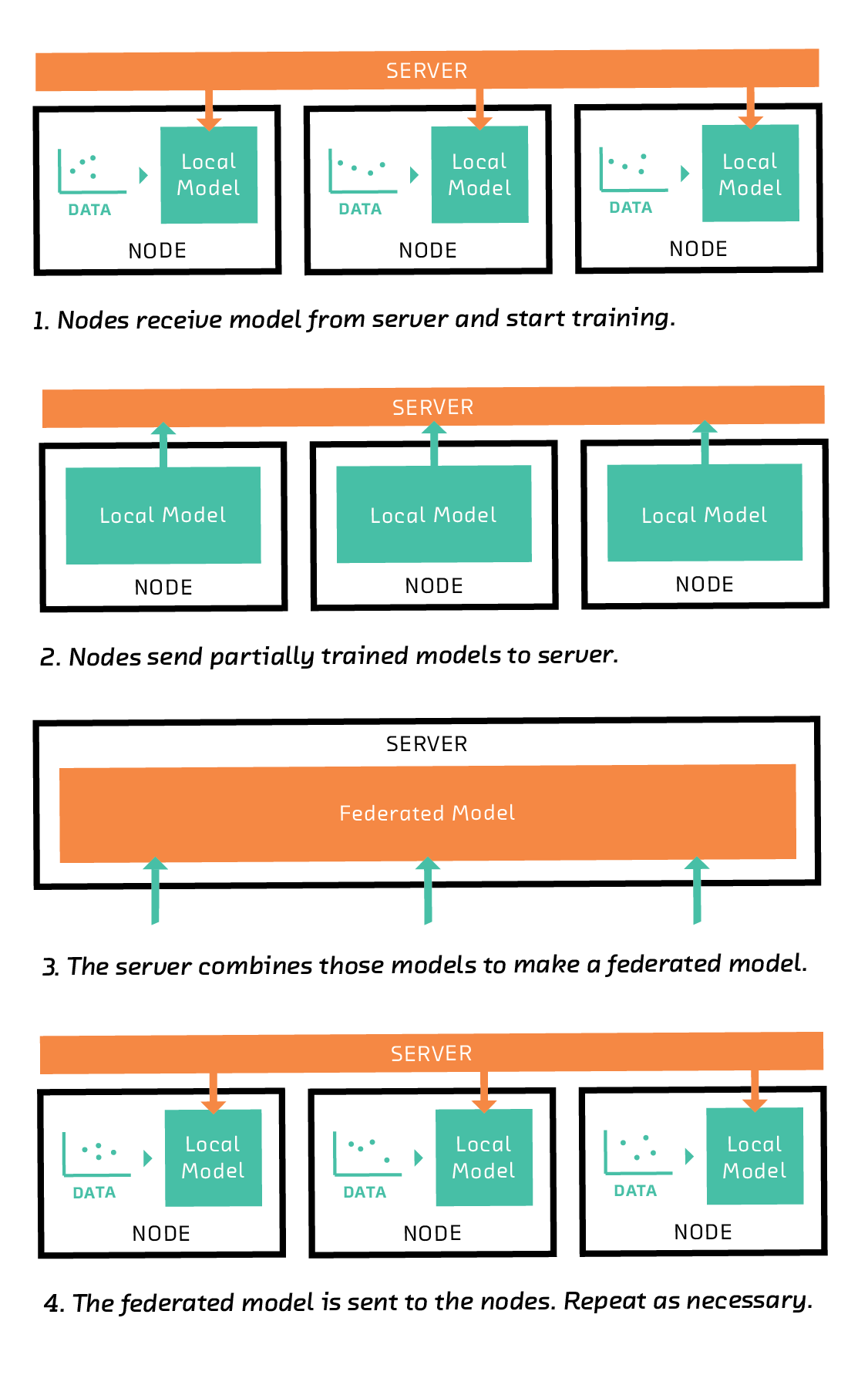
Here is simple Federated Averaging algorithm which accumlates the updated from clients into global model.

In what tasks is federated learning best suited.
- The task labels don’t require human labelers but are naturally derived from user interaction.
- The training data is privacy sensitive.
- The training data is too large to be feasibly collected centrally.
Easy enough?
At first, the training over this decentralized approach looks simple enough and similar to distributed machine learning approaches. But there are some major differences to applications in data centers where the training data is distributed among many machines.
- Unbalanced and Non IID training samples
The data obtained from different users local dataset will not be representative of the population distribution and vary from user to user thus creating imbalance data for training.
- High number of clients
Since, deep learning algorithms are data hungry, applicated using federated learning require a lot of clients. The data from these many users will be far greater than the typically centrally stored data.
- Slow and Unreliable network connections
Due to varying upload and download speed across different regions and different countries, the uploads required in federated learning will be very slow compared to traditional distributed machine learning in datacenters where the communications among the nodes is very quick and messages don’t get lost (Remember, Imagenet training in 5 mintues).
Compression
Clearly, there is a quite of overhead in communication between client and server given there is unreliable and slow network connections speed. The typical neural networks have millions of parameters nowadays. Sending updates for so many values to a server leads to huge communication costs with a growing number of users and iterations. So, to reduce the uplink communication cost, McMahan and group proposes two methods outlined in this paper. These are the compression techniques which encode updates with fewer bits, as only updates are communicated to server for averaging.
Sketeched Updates
In this method, each user calculates it’s update after training on it’s local data, and then before sending the updates to the server, the updates are compressed using a combination of quantization, random rotations and subsampling techniques outlined in the paper.
Structured Updates
This second type of compression method restricts the updates to a restricted space such as making each update low-rank with at most rank k or using random mask on updates making it a sparse matrix, and only sending the non-zero entries.
These both methods can be used to reduce the communication overhead and also reduce the size of updates for each round making it reliable even at low upload speeds.
Applications
- Smartphones
Smartphones have revolutionalized the data generation capability with growing number of users hooking on the device each year. (Did you know? There are an estimated 3 billion smartphones in the world, and 7 billion connected devices). With more data, comes more machine learning. Machine learning have provided a lot of cool applications such as Smart Reply, Image Recognition, next word prediction, and many more on smartphones. But this comes at the cost of data and data collection has been heavily relied on private, sensitive user data. Sure, we can make use of synthetic data, but it doesn’t capture all the scenarios occuring in real world data. Users (if are aware of any such usage) are reluctant in sharing such sensitive information which corporations capture (in process making it known or unknown to users) in exchange for smartness. With help of federated learning, the data never leaves the device and model gets trained on large amounts of data.
- Healthcare
This is the field where anonymity plays a very crucial. The consequences of actual and potential privacy violations can be serious. By keeping the training data in the hands of patients or providers, federated learning has the potential to make it possible to collaboratively build models that save lives and generate huge value.
Federated Learning Case Study Gboard
We will look into one case study of improving suggestions on Gboard done at Google. Authors of the paper used federated learning(FL) for search query suggestions on Gboard. The goal is to improve query click-through-rate (CTR) by taking suggestions from the baseline model and removing low quality suggestions through the triggering model.
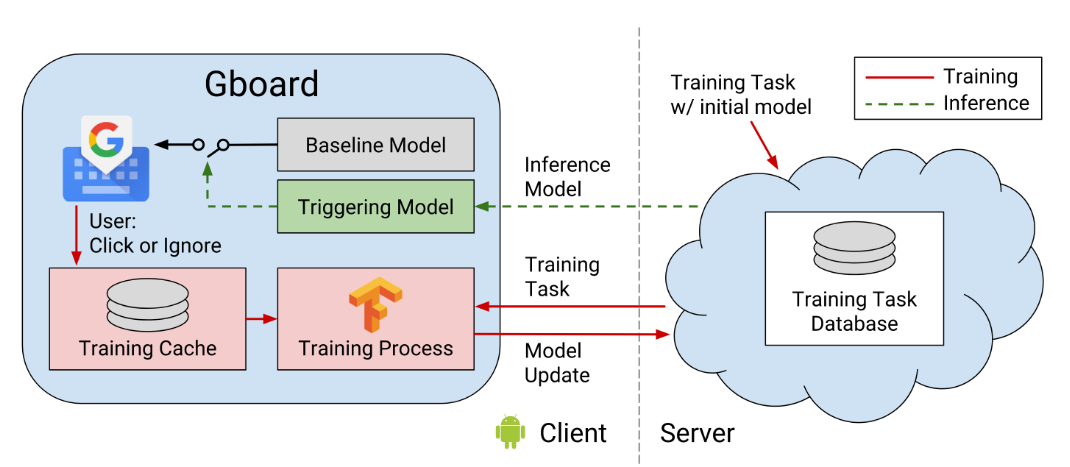
The use case is to train a model that predicts whether query suggestions are useful, in order to filter out less relevant queries. The training data collected for this model by observing user interactions with the app: when surfacing a query suggestion to a user, a tuple(features; label) is stored in an on-device training cache, a SQLite based database. Here, features is collection of query and context related information and label is user action of {clicked, ignored}. This data is then used for on-device training and evaluation by servers. The model is trained typically at night time when phone is charging, idle and connected to WiFi network.
The baseline model is traditional server-based machine learning that generates query suggestion candidates by matching the user’s input to an on-device subset ofthe Google Knowledge Graph (KG). It then scores these suggestions using a Long Short-Term Memory network trained on an offline corpus of chat data to detect potential query candidates. This LSTM is trained to predict the KG category of a word in a sentence and returns higher scores when the KG category of the query candidate matches the expected category. The highest scoring candidate from the baseline model is selected and displayed as a query suggestion (an impression). The user then either clicks on or ignores the suggestion and users interaction is stored in on-device training cache to be used by FL for training.
The task of the federated trained model is designed to take in the suggested query candidate from the baseline model, and determine if the suggestion should or should not be shown to the user. This FL model is triggering model. The output of model is a score for a given query, with higher scores meaning greater confidence in the suggestion.
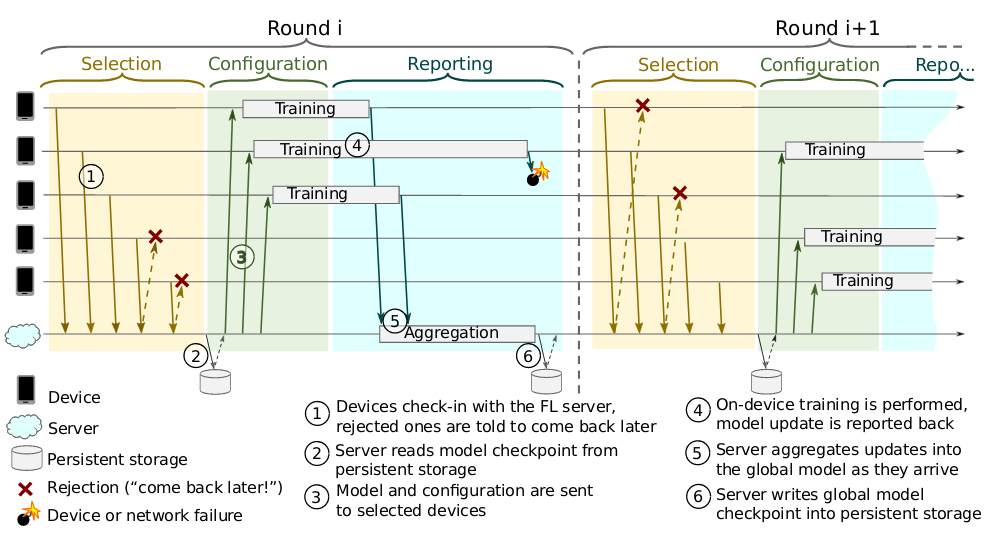
Here are the steps that are performed in training and updating the global model,
-
The participants in the training are clients(or devices) and FL server which is cloud-based distributed service. Clients announces to the server that they are ready to run FL task for a given FL population. An FL population is specified by a globally unique name which identifies the learning problem, or application, which is worked upon. An FL task is a specific computation for an FL population, such as training to be performed with given hyperparameters, or evaluation of trained models on local device data. Sever selects some number of clients to run FL task.
-
The server tells the selected devices what computation to run with an FL plan, a data structure that includes a TensorFlow graph and instructions for how to execute it. Once a round is established, the server next sends to each participant the current global model parameters and any other necessary state as an FL checkpoint.
-
Each participant then performs a local computation based on the global state and its local dataset, and sends an update in the form of an FL checkpoint back to the server.
-
The server incorporates these ephemeral updates are aggregated using the Federated Averaging algorithm into its global state, and the process repeats until convergence. Upon convergence, a trained checkpoint is used to create and deploy a model to clients for inference.
This is one such example demonstrating end-to-end training in FL with decentralized data. We all love end-to-end learning tasks, don’t we?
Here is another application of next word prediction which we had seen in RNN before, where federation learning can be used. Important result obtained is board is neural language model trained using FL demonstrated better performance than a model trained with traditional server-based collection and training.
Privacy
Privacy, the one word which is promised by everyone but delievered by … (I will let you complete it). It’s no surprise that, In Age of Internet, with great promises of personalization comes greater responsibility of privacy. (Thanks privacy vigilant Uncle Ben)

Here is the template quote to put any of your favourite buzzwords at the start, I will put Privacy and see if it makes sense,
Privacy is like teenage s**: everyone talks about it, nobody knows how to do it, everyone thinks everyone else is doing it & so claims to do it.
It does make sense after all.
In contrast to traditional approach of uploading data to server, FL approach has clear privacy advantages:
- Only the minimal information necessary for model training (the model parameter deltas) is transmitted. The updates will never contain more information than the data from which they derive, and typically will contain much less.
- The model update is ephemeral, lasting only long enough to be transmitted and incorporated into the global model. Thus while the model aggregator needs to be trusted enough to be given access to each client’s model parameter deltas, only the final, trained model is supplied to end users for inference. Typically any one client’s contribution to that final model is negligible.
A simple join between an anonymized datasets and one of many publicly available, non-anonymized ones, can re-identify anonymized data. What do I mean by that? Let me explain with the classic example of Netflix. In 2007, Netflix offered $1 Million prize money by hosting competition on Kaggle with objective to achieve a 10% improvement in its recommedation system. The data that Netflix provided for competition consits of movie rating on scale 1 to 5 for 480189 users. In order to protect their customer’s privacy, they removed personal information and replaced IDs with random IDs. But probing into dataset further, researchers linked the Netflix dataset with IMDb to de-anonymize the Netflix dataset using the dates on which a user rated certain movies and the result was they successfully identified the Netflix records of known users, uncovering their apparent political preferences and other potentially sensitive information.
The most indirect way to infer information about the training data requires only the ability to query the model several times. Anyone with indirect access to the model via an API can attempt to attack it in this way. This attack vector is not unique (or any more dangerous) in federated learning.
Your data is your reflection.
Now the question we all want answer to Is the data communicated through federated learning really anonymous and secured? There are primarily two methods, namely secure aggregation and differential privacy to ensure that the data communicated stays anonymized.
Secure Aggeration
Secure Aggregation uses Secure Multi-Party Computation protocol that uses encryption to make individual devices’ updates uninspectable by a server, instead only revealing the sum after a sufficient number of updates have been received as outlined in this paper. With secure aggregation, client’s updates are securely summed into a single aggregate update without revealing any client’s individual component even to the server. This is accomplished by cryptographically simulating a trusted third party.
Secure Aggregation is four-round interactive protocol enabled during the reporting phase of a given FL round shown above, which means it will grow quadratically with the number of users, most notably the computational cost for the server. In each protocol round, the server gathers messages from all devices in the FL round, then uses the set of device messages to compute an independent response (final aggregation) to return to each device. This protocol is robust to a significant fraction of devices dropping out which maybe the case where there is poor network connection or the phone is not idle anymore. The first two rounds constitute a Prepare phase, in which shared secrets are established and during which devices who drop out will not have their updates included in the final aggregation. The third round constitutes a Commit phase, during which devices upload cryptographically masked model updates and the server accumulates a sum of the masked updates. All devices who complete this round will have their model update included in the protocol’s final aggregate update, or else the entire aggregation will fail. The last round of the protocol constitutes a Finalization phase, during which devices reveal sufficient cryptographic secrets to allow the server to unmask the aggregated model update. Not all committed devices are required to complete this round; so long as a sufficient number of the devices who started to protocol survive through the Finalization phase, the entire protocol succeeds.
By using cryptography techniques, it is possible to ensure that the updates of individuals can only be read when enough users submitted updates. This makes man-in-the-middle attacks much harder: An attacker cannot make conclusions about the training data based on the intercepted network activity of an individual user.
Differential Privacy
Differential privacy techniques can be used in which each client adds a carefully calibrated amount of noise to their update to mask their contribution to the learned model. To avoid the disaster like Netflix join, differential privacy formalizes the idea that any query to database should not reveal any hints whether one person is present in dataset and what their data is. There are lot many techniques such as Randomized Response, Lapalace mechanism and RAPPOR. In short, in Differential Privacy, privacy is guaranteed by the noise added to the answers.
Here is algorithm for Differentially private SGD from paper,

For more on Differential Privacy, here is the paper, Differential Privacy for dummies, Florian blog excellent introduction on differential privacy and CleverHans has a good blog on introduction to Privacy and ML.
Both these approaches add communication and computation overhead, but that may be a trade-off worth making in highly sensitive contexts.
Code
All talk, no code?
We implemented federated learning using two frameworks Tensorflow and PyTorch with PySyft library.
Using PyTorch + PySyft, we are able to achieve Federated Learning model by making changes to just 10 lines of traditional CNN Pytorch model. So, cool!
Here we create two clients, named Alice and Bob,
import syft as sy # <-- import the Pysyft library
hook = sy.TorchHook(torch) # <-- hook PyTorch ie add extra functionalities to support Federated Learning
bob = sy.VirtualWorker(hook, id="bob") # <-- define remote worker bob
alice = sy.VirtualWorker(hook, id="alice") # <-- and alice
We distribute the dataset across both the clients
federated_train_loader = sy.FederatedDataLoader( # <-- this is now a FederatedDataLoader
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
.federate((bob, alice)), #we distribute the dataset across all the workers, it's now a FederatedDataset
batch_size=args.batch_size, shuffle=True)
After training this for 10 rounds, we achieve same accuracy as by traditional CNN Pytorch Model and in very less time.
🍻 Cheers to Privacy!
Happy Learning!
Further Reading
Must Read! Florian’s blog on Federated Learning, Differential Privacy and Federated Learning for Firefox
Must Read! Communication-Efficient Learning of Deep Networks from Decentralized Data
Towards Federated Learning at scale: System Design
Federated Learning: Strategies for Improving Communication Efficiency
Google Blog on Federated Learning
Applied Federated Learning:Improving Google Keyboard Query Suggestions
Federated Learning for Mobile Key Prediction
Learning differentially private language models without losing accuracy
Netflix Dataset De-anonymization
Practical Secure Aggregation for Privacy-Preserving Machine Learning
Deep Learning with Differential Privacy
Differential Privacy for dummies
CleverHans blog Privacy and ML
Differential Privacy and Machine Learning:a Survey and Review
LEAF: A Benchmark for Federated Settings
Tensorflow Dev Summit : Federated Learning
Footnotes and Credits
Gboard and Federated Learning protocol
Federated Learning in short graphics and privacy
Differentially private SGD Algorithm
NOTE
Questions, comments, other feedback? E-mail the author