Training LLMs on multiple GPUs involves both computation and communication. A previous blog on sharding looked at various ZeRO stage techniques that partition model states across multiple GPUs. Computation and communication must be distributed across multiple GPUs or even multiple nodes. In this setting, communication overhead can easily become a bottleneck: synchronizing parameters, exchanging gradients, or gathering outputs across GPUs can dominate training time if not managed carefully.
Inter-node and Intra-node communication
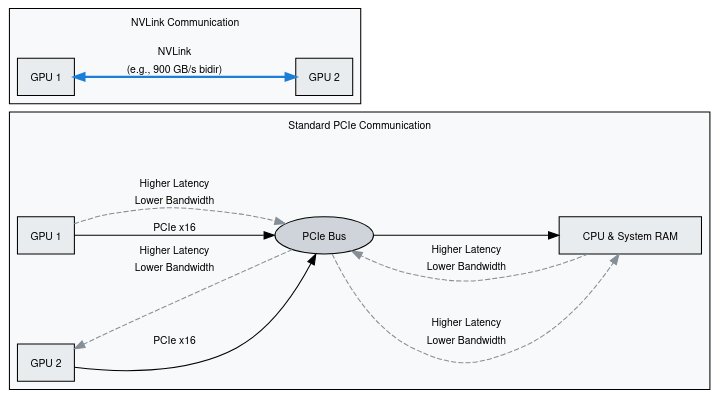
In modern computers, different components need high-speed ways to exchange data. The CPU connects to main memory through a dedicated memory bus, while devices like GPUs, SSDs, and NICs usually connect through PCI Express (PCIe). PCIe is a general interface standard for connecting high-speed components. There are also specialized links like NVLink (NVIDIA) and Infinity Fabric (AMD) that provide higher bandwidth and lower latency than PCIe. Before NVLink, GPU-to-GPU transfers often traversed PCIe and CPU memory, adding extra latency; NVLink enables more direct peer-to-peer transfers.
ApX Machine Learning LLM course
A GPU node is a server equipped with one or more GPUs, typically used for high-performance computing or AI workloads. A GPU cluster is a collection of such nodes connected together, often along with CPU-only nodes, to provide scalable compute power. Larger LLMs that don’t fit a single node require a GPU cluster to train. Communication latency and bandwidth differ dramatically between intra-node (within a node) and inter-node (across multiple nodes). The speed of communication between GPUs within the same node (intra-node) is much higher than communication across different nodes (inter-node). On modern NVIDIA GPU servers, intra-node links often use NVLink, a high-bandwidth interconnect that provides far greater bandwidth and lower latency than PCIe. InfiniBand is often used for inter-node links. Efficient model partitioning must account for these differences to minimize slow inter-node transfers.
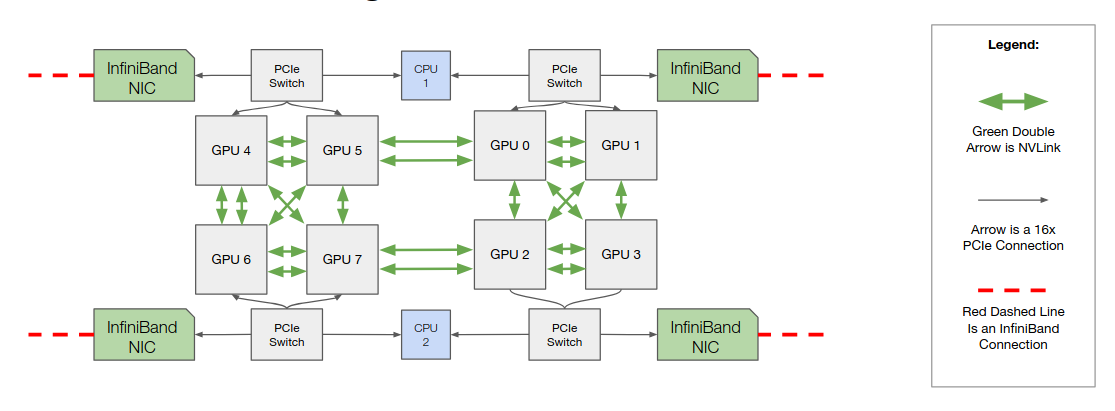
For curious readers, NVIDIA also provides NVSwitch, which builds on NVLink to provide higher-bandwidth connectivity and switch-style topologies inside a node. See this NVLink history blog for a generational overview.
Libraries
Several libraries implement the collective communications needed for distributed training:
- MPI — the Message Passing Interface is a general-purpose communication standard. Implementations such as OpenMPI support CUDA-aware transfers for GPU-to-GPU communication.
- NCCL — NVIDIA’s library (NCCL) is optimized for GPU collectives and typically gives the best performance on NVIDIA hardware.
- Gloo — developed by Meta, Gloo provides CPU and GPU collectives and is used by some frameworks as an alternative backend.
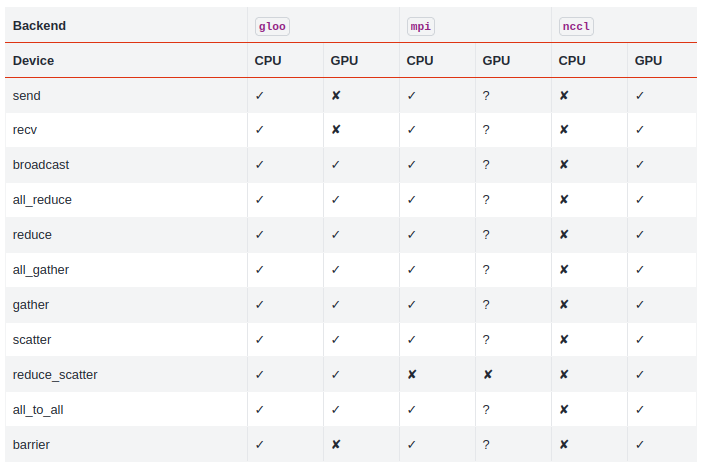
PyTorch docs
torch.distributed exposes multiple backends for distributed training. PyTorch documentation recommends using gloo as backend for distributed CPU training and nccl for distributed GPU training.
Benchmarking
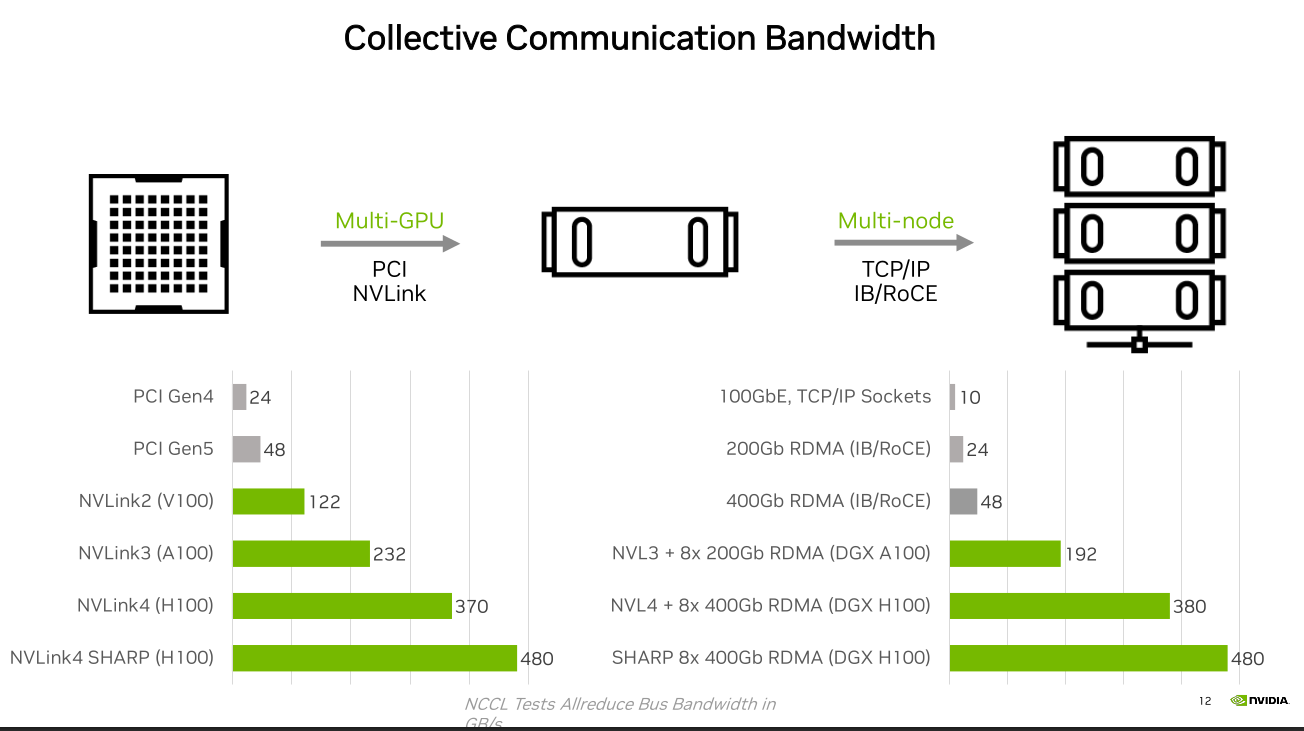
NVIDIA advertises theoretical NVLink bandwidth. NVLink 5 promises 1.8 TB/s bidirectional per GPU (900 GB/s in each direction), aggregated across 18 NVLink 5 links. Modern GPUs have multiple ports, enabling several simultaneous connections. A simple analogy: each NVLink port is a highway with 100 GB/s capacity; 18 ports are like 18 highways connecting the GPU to others, carrying 1.8 TB/s in total.
nccl-tests provides utilities to benchmark collective operations. Stas Bekman’s ML Engineering book and the ElutherAI cookbook benchmarks include useful scripts for measuring latency and bandwidth.
I created an Ansible playbook to benchmark intra-node and inter-node performance using nccl-tests and Stas Bekman’s scripts.
To test, I provisioned a 4×H100 instance on Lambda Labs. The benchmarking run cost approximately $5. Here is the nvidia-smi output,
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.148.08 Driver Version: 570.148.08 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA H100 80GB HBM3 On | 00000000:06:00.0 Off | 0 |
| N/A 34C P0 70W / 700W | 0MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA H100 80GB HBM3 On | 00000000:07:00.0 Off | 0 |
| N/A 30C P0 70W / 700W | 0MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
| 2 NVIDIA H100 80GB HBM3 On | 00000000:08:00.0 Off | 0 |
| N/A 29C P0 70W / 700W | 0MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
| 3 NVIDIA H100 80GB HBM3 On | 00000000:09:00.0 Off | 0 |
| N/A 32C P0 70W / 700W | 0MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
Sure enough there are 4xH100 GPUs each with 80GB memory 💰💰 .
Next, the output of nvidia-smi topo -m command shows how the GPUs are inter-linked with each other and how data travels between GPUs.
GPU0 GPU1 GPU2 GPU3 NIC0 CPU Affinity NUMA Affinity GPU NUMA ID
GPU0 X NV18 NV18 NV18 PHB 0-103 0 N/A
GPU1 NV18 X NV18 NV18 PHB 0-103 0 N/A
GPU2 NV18 NV18 X NV18 PHB 0-103 0 N/A
GPU3 NV18 NV18 NV18 X PHB 0-103 0 N/A
NIC0 PHB PHB PHB PHB X
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
NIC Legend:
NIC0: mlx5_0
The output shows the each GPU is connected to other using NVLink. GPU0 for example is connected to GPU1, GPU2 and GPU3 using NVLink connection.
The playbook then benchmarks common collective operations like all-reduce and reduce-scatter to verify intra-node and inter-node performance. In the next post, we’ll explain these operations in detail.
All-reduce benchmarking was run via:
NCCL_DEBUG=INFO mpirun -np 1 ./build/all_reduce_perf -b 8 -e 1G -f 2 -g 4
In this setup, all_reduce benchmarking is performed using various payload sizes increasing from 8 bytes to 1G. a single MPI process controls all 4 GPUs on the node. Communication between GPUs uses intra-process transport (peer-to-peer via NVLink or PCIe). This configuration is ideal for single-node benchmarks with multiple GPUs. For multi-node setups, each node typically runs one MPI process per GPU, with NCCL leveraging MPI or another bootstrap for cross-node communication.
The NCCL_DEBUG=INFO flag enables verbose logging, which provides additional insight into communicator initialization, topology detection, and performance results.
# Collective test starting: all_reduce_perf
# nThread 1 nGpus 4 minBytes 8 maxBytes 1073741824 step: 2(factor) warmup iters: 1 iters: 20 agg iters: 1 validation: 1 graph: 0
#
# Using devices
# Rank 0 Group 0 Pid 16629 on 192-222-52-239 device 0 [0000:06:00] NVIDIA H100 80GB HBM3
# Rank 1 Group 0 Pid 16629 on 192-222-52-239 device 1 [0000:07:00] NVIDIA H100 80GB HBM3
# Rank 2 Group 0 Pid 16629 on 192-222-52-239 device 2 [0000:08:00] NVIDIA H100 80GB HBM3
# Rank 3 Group 0 Pid 16629 on 192-222-52-239 device 3 [0000:09:00] NVIDIA H100 80GB HBM3
192-222-52-239:16629:16629 [0] NCCL INFO Bootstrap: Using eno1:172.27.124.124<0>
192-222-52-239:16629:16629 [0] NCCL INFO cudaDriverVersion 12080
192-222-52-239:16629:16629 [0] NCCL INFO NCCL version 2.26.2+cuda12.8
192-222-52-239:16629:16652 [0] NCCL INFO NET/Plugin: Could not find: libnccl-net.so. Using internal net plugin.
192-222-52-239:16629:16652 [0] NCCL INFO NCCL_IB_DISABLE set by environment to 1.
192-222-52-239:16629:16652 [0] NCCL INFO NET/Socket : Using [0]eno1:172.27.124.124<0>
192-222-52-239:16629:16652 [0] NCCL INFO PROFILER/Plugin: Could not find: libnccl-profiler.so.
....
192-222-52-239:16629:16655 [3] NCCL INFO Trees [0] -1/-1/-1->3->2 ...
192-222-52-239:16629:16655 [3] NCCL INFO P2P Chunksize set to 524288.
...
Channel 00/0 : 2[2] -> 3[3] via P2P/direct pointer
...
This shows 4xH100 GPUs on a single node are used for benchmarking. NCCL is able to identify and assign a rank for each GPU. NCCL will use Socket transport because IB (InfiniBand) is disabled (NCCL_IB_DISABLE=1) and no net plugin is found. For single-node H100, Socket is fine, but if this were multi-node, IB would be faster.
NCCL sets up ring and tree topologies for efficient communication. For intra-node, it uses peer-to-peer memory (P2P) via NVLink/PCIe. Channel 00/0 : 2[2] -> 3[3] means GPU 2 sends to GPU 3 over direct memory. NCCL splits data into 512KB chunks for P2P communication.
# out-of-place in-place
# size count type redop root time algbw busbw #wrong time algbw busbw #wrong
# (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s)
8 2 float sum -1 26.08 0.00 0.00 0 24.37 0.00 0.00 0
16 4 float sum -1 24.02 0.00 0.00 0 23.59 0.00 0.00 0
32 8 float sum -1 23.50 0.00 0.00 0 24.45 0.00 0.00 0
64 16 float sum -1 24.29 0.00 0.00 0 23.91 0.00 0.00 0
128 32 float sum -1 24.38 0.01 0.01 0 23.58 0.01 0.01 0
256 64 float sum -1 24.54 0.01 0.02 0 23.46 0.01 0.02 0
512 128 float sum -1 23.65 0.02 0.03 0 23.52 0.02 0.03 0
1024 256 float sum -1 23.85 0.04 0.06 0 23.30 0.04 0.07 0
2048 512 float sum -1 23.60 0.09 0.13 0 23.61 0.09 0.13 0
4096 1024 float sum -1 24.63 0.17 0.25 0 28.19 0.15 0.22 0
8192 2048 float sum -1 25.22 0.32 0.49 0 23.96 0.34 0.51 0
16384 4096 float sum -1 23.78 0.69 1.03 0 24.17 0.68 1.02 0
32768 8192 float sum -1 24.40 1.34 2.01 0 23.62 1.39 2.08 0
65536 16384 float sum -1 24.56 2.67 4.00 0 24.78 2.64 3.97 0
131072 32768 float sum -1 24.62 5.32 7.98 0 24.81 5.28 7.93 0
262144 65536 float sum -1 26.80 9.78 14.67 0 26.37 9.94 14.91 0
524288 131072 float sum -1 26.67 19.66 29.49 0 32.61 16.08 24.12 0
1048576 262144 float sum -1 28.06 37.36 56.05 0 27.36 38.32 57.48 0
2097152 524288 float sum -1 32.05 65.43 98.15 0 32.07 65.39 98.09 0
4194304 1048576 float sum -1 45.05 93.10 139.65 0 44.39 94.48 141.72 0
8388608 2097152 float sum -1 65.19 128.68 193.03 0 64.75 129.56 194.33 0
16777216 4194304 float sum -1 104.4 160.69 241.03 0 101.9 164.72 247.07 0
33554432 8388608 float sum -1 174.9 191.85 287.78 0 174.9 191.90 287.85 0
67108864 16777216 float sum -1 326.6 205.47 308.21 0 327.1 205.15 307.72 0
134217728 33554432 float sum -1 614.7 218.34 327.51 0 615.8 217.95 326.92 0
268435456 67108864 float sum -1 1184.9 226.54 339.81 0 1187.0 226.15 339.22 0
536870912 134217728 float sum -1 2314.9 231.92 347.88 0 2319.5 231.46 347.20 0
1073741824 268435456 float sum -1 4525.6 237.26 355.89 0 4557.5 235.60 353.40 0
# Out of bounds values : 0 OK
# Avg bus bandwidth : 98.414
A couple of observations,
- Small messages (<64 KB) are dominated by latency, so bandwidth is almost zero.
- Larger messages (≥1MB) start saturating the GPU interconnect.
- At 1 GB :
algbw~ 237 GB/s (aggregate across 4 GPUs) andbusbw~ 355 GB/s (corresponds to ~ 40% of H100’s theoretical NVLink aggregate 900 GB/s).
nccl-tests provides a performance guide that explains algbw, busbw, and other reported metrics in detail.
Here is a smaller benchmark from the ml-engineering scripts:
Environment:
- software: torch=2.7.0, cuda=12.8, nccl=(2, 26, 2)
- hardware: _CudaDeviceProperties(name='NVIDIA H100 80GB HBM3', major=9, minor=0, total_memory=81089MB, multi_processor_count=132, uuid=4dbfbb99-983a-79af-8527-ca9f0c139426, L2_cache_size=50MB)
The average bandwidth of all_reduce over 4 ranks (5 warmups / 20 trials):
| payload | busbw | algbw |
| ------: | ---------: | ---------: |
| 32KiB | 1.18GBps | 0.79GBps |
| 64KiB | 2.44GBps | 1.63GBps |
| 128KiB | 4.72GBps | 3.15GBps |
| 256KiB | 9.66GBps | 6.44GBps |
| 512KiB | 18.84GBps | 12.56GBps |
| 1MiB | 34.50GBps | 23.00GBps |
| 2MiB | 60.60GBps | 40.40GBps |
| 4MiB | 99.65GBps | 66.43GBps |
| 8MiB | 154.14GBps | 102.76GBps |
| 16MiB | 208.99GBps | 139.33GBps |
| 32MiB | 258.95GBps | 172.63GBps |
| 64MiB | 293.25GBps | 195.50GBps |
| 128MiB | 317.31GBps | 211.54GBps |
| 256MiB | 335.62GBps | 223.75GBps |
| 512MiB | 345.78GBps | 230.52GBps |
| 1GiB | 355.72GBps | 237.15GBps |
| 2GiB | 360.91GBps | 240.61GBps |
| 4GiB | 363.27GBps | 242.18GBps |
| 8GiB | 365.21GBps | 243.47GBps |
| 16GiB | 366.99GBps | 244.66GBps |
The network throughput observed will never be same as the advertised theoretical throughput. One should expect in best case to expect about 80%-90% of advertised value.
There are few knobs in form of environment variables that can be tuned to maximise the utilization.
NVIDIA talk
The gap between intra-node and inter-node throughput is narrowing with recent hardware and software improvements.
Stas Bekman’s ML Engineering book, particularly the chapter on networking provides detailed insights into hardware differences across vendors. I highly recommend curious readers to give it read. Also recommend the talk) and the paper on NCCL.
In the next post we will introduce common communication patterns used in distributed training (ring all-reduce, tree reductions, reduce-scatter + all-gather) and explain when to use each pattern.