Hugging Face released a fantastic open-source book for training LLMs on up to 12,000 GPUs.
Let’s take a step back and understand what it takes to train an LLM on a single GPU. A training loop for LLMs - any deep neural network - consists of 3 steps
- Forward pass: Pass inputs through the network to get outputs. This output is used to calculate loss by comparing it to ground truth.
- Backward pass: Calculate gradients using the loss and propagate these gradients all the way to the first layer of the model
- Optimization step: Update the parameters of the network using the gradients.
Shown below is an example of a training loop in PyTorch
def train_one_epoch(epoch_index: int):
for i, batch in enumerate(training_loader):
inputs, labels = batch
# Zero gradients every batch
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
# Compute the loss
loss = loss_fn(outputs, labels)
# Backward pass
loss.backward()
# Adjust learning weights - optimizer step
# Updates both - model parameters and optimizer states
optimizer.step()
...
Memory consumption
During the training of a neural network, following items are stored in the memory
- Model weights
- Model gradients
- Optimizer states
- Activation required to compute gradients
These come in different shapes and precisions. The precision here refers to space required to store the tensor values FP32 - 4 bytes, BP16 - 2 bytes and FP8 - 1 byte.
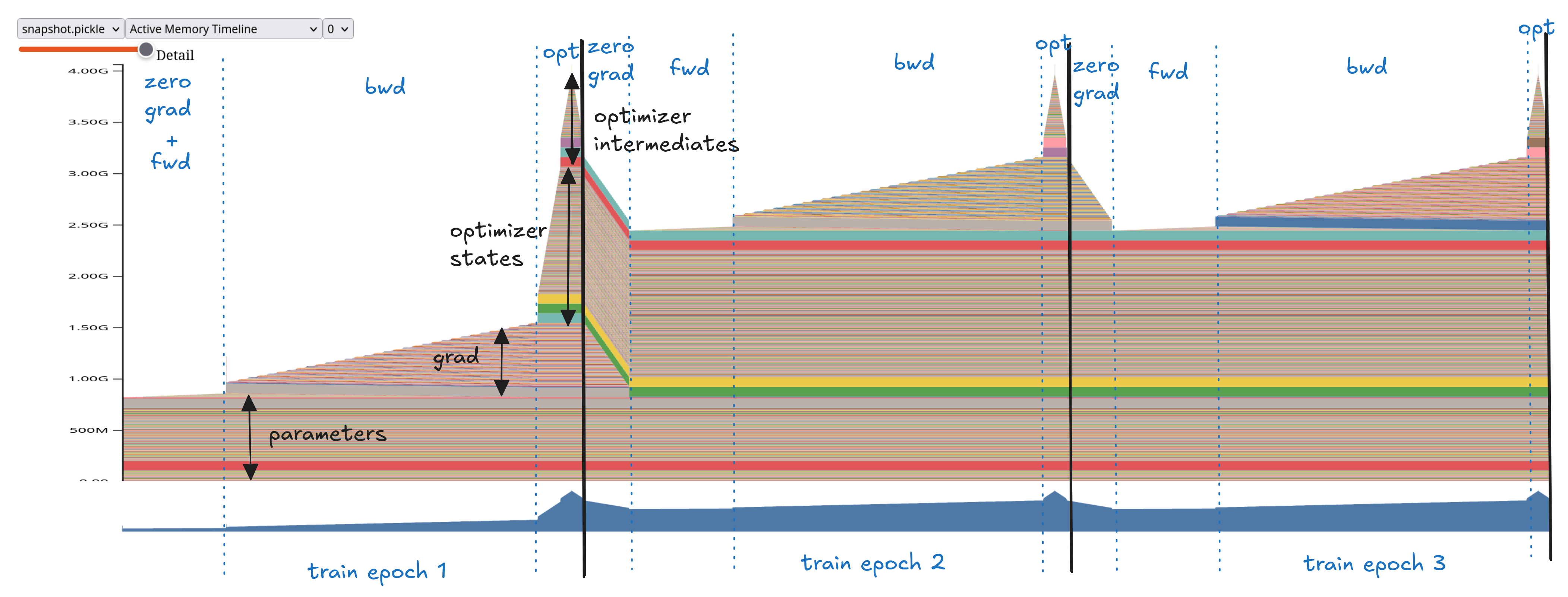
We use PyTorch profiler to understand memory utilization during training. A typical trend observed is:
- A slight increase in memory during the forward pass.
- Gradual memory buildup during the backward pass as gradients are computed.
- A large spike during the first epoch when optimizer states are lazily initialized.
- In later epochs, optimizer states are updated in-place, so their memory footprint remains constant.
- Gradient memory is freed when
zero_grad()is called.
Code to inspect memory utilization: Readme
The memory taken by activation seems insignificant for our example 360M parameter model above. Once we scale the size of the model and increase the the sequence length, activation memory becomes the memory bottleneck.
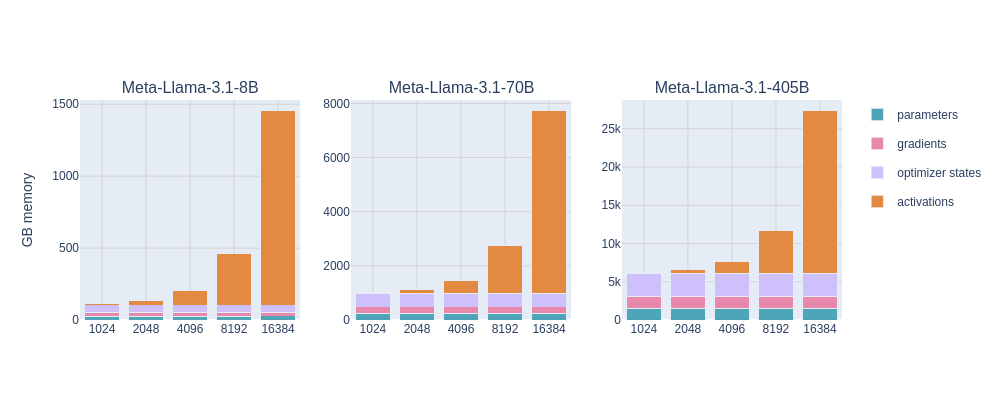
HuggingFace blog
How can we tackle this “activation explosion”? There are two approaches that we will look into
-
Activation Recomputation
-
Gradient Accumulation
Activation Recomputation
The idea behind activation recomputation (also known as gradient checkpointing) is to reduce memory usage during training by not storing all intermediate activations in memory during the forward pass. Instead, some or all activations are recomputed on-the-fly during the backward pass, when they are needed to compute gradients. There is a trade-off between memory and computation where we are saving memory at the cost of additional computation, as parts of the forward pass are re-executed during backpropagation.
There are two types of strategies
-
Full : In this approach, we discard all the activation and recompute them again during the backward pass. This strategy saves the most memory but adds a 30-40% compute time overhead.
-
Selective: In the Reducing activation memory in Large Language Models paper, the authors propose to checkpoint only those parts that take up a significant amount of memory but are cheap to compute for each transformer layer. Attention operations have large memory footprint for larger input sizes and can be recomputed efficiently. Using selective recomputation, GPT-3 (175B) model reduces the memory usage by up to 70% while adding only a 2.7% computation time overhead.

Full and selective activation
There is nice interactivate plot in the Activation recompuation section of the playbook. It shows differences in the memory usage for None, Full and Selective activation recomputation strategies for various model sizes.
This memory-compute trade-off is especially advantageous on GPU-accelerated hardware, where memory access is slower than raw computation speed (FLOPS). It makes sense to recompute rather than store in many cases.
Gradient Accumulation
Activation recomputation reduces memory usage within a single forward-backward pass. But when we increase batch size, memory usage grows again—because activation memory scales linearly with batch size: each input in the batch needs its own set of activations for backpropagation.
Gradient accumulation addresses this by breaking down large batch size into small micro batches. We perform forward and backward pass on each micro-batch and sum (or average) the gradients of all the micro-batch - accumulating the gradients - before updating the parameters by taking an optimizer step. It helps reducing the memory of activations by computing only partial, micro-batches.
This approach reduces activation memory usage because only one micro-batch’s activations need to be stored in memory at a time. The downside is that multiple forward and backward passes are needed, which increases compute time and slows training.
However, one important observation is that each micro-batch can be processed independently and in parallel, which sets the stage for scaling beyond a single GPU.
In next post on the ultra-scale playbook series, we will dive into the first pattern of distributed training of LLMs - Data Parallelism!.