Recurrent Neural Networks
In this post, we will see if Neural Networks can write as good as Shakespeare?
All the codes implemented in Jupyter notebook in Keras, PyTorch and Fastai.
All codes can be run on Google Colab (link provided in notebook).
Hey yo, but how?
Well sit tight and buckle up. I will go through everything in-detail.

Feel free to jump anywhere,
Here, let me borrow some of the points from Prof. Yuval Noah Harrari’s book on Sapiens,
How did Homo sapiens came to dominate the planet? The secret was a very peculiar characteristic of our unique Sapiens language. Our language, alone of all the animals, enables us to talk about things that do not exist at all. You could never convince a monkey to give you a banana by promising him limitless bananas after death, in monkey heaven.
By combining profound insights with a remarkably vivid language, Sapiens acquired cult status among diverse audiences, captivating teenagers as well as university professors, animal rights activists alongside government ministers.
Introduction to Recurrent Neural Networks
A long time ago in a galaxy far, far away….

I-know-everything: So, Padwan today we are going to study about language through the lens of Neural Networks. Let me get philosophical for a bit, and show how we are what today because we are able to communicate which each other the ideas, the ideas to push the human race forward. Language has been a critical cornerstone to the foundation of human mankind and will also play a critical role in human-computer world. (Blocking terminator vibes, transmitting JARVIS vibes….)
I-know-nothing: Does this mean that it will be the case where image where computer understand only numbers, the underlying language will also be converted to numbers and where some neural network does it’s magic?
I-know-everything: Bingo, that’s exactly right. As image understanding has it’s own challenges like occlusion, viewpoint variation, deformations, background clutter, etc. which we saw in both image classification and object detection, dealing with language comes with it’s own challenges, starting from what language we are dealing with. This is what Natural Language Processing (NLP) field is about.
Let me jump and give you about the idea of what is Force of RNN . RNN known as recurrent neural networks or Elman Network are useful for dealing with sequential information.
I-know-nothing: Why a new network, can’t we just use the old Force of MLP or Force of CNN? for dealing with these sequential information? What’s so special about sequential information? What makes RNN special to dealing with these types of data?
I-know-everything: Aha, as we will see later, indeed we can use Force of CNN for dealing with sequential data but Force of MLP fails to capture relationships found in sequential data. There are different types of sequential data (where some sort of sequence is present) like time series, speech, text, financial data, video, etc. These are sequential data are not independent but rather sequentially correlated. For e.g. given a sequence, The cat sat on mat. Here, from given example we come to a conclusion that cat is sitting on mat. So, there is some context, which is nearby values of the data are related to each other. This is one example of sequential data and we can see how the context in such sequetial data matters to understand sequences. Same can be said for video, audio or any other sequential i.e. sequence involving data.
- What makes RNN special?
This will take us on a journey to understand what are RNN. How they so effectively learn sequential data and what can we use them for?
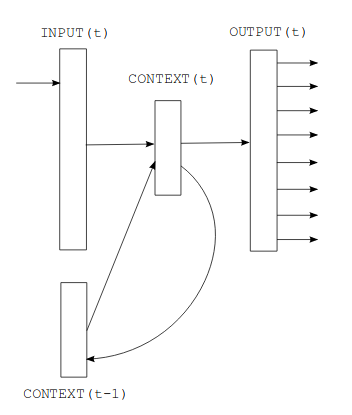
So, what can we infer by looking at the figure above. There is some context(t) which take in two inputs, Input(t) and context(t-1), which then produces output(t). Also, context(t-1) gets updated to context(t). There is some form of recursion. This is a Simple RNN which take in sequence input, to produce output, where context(t-1) is known as state. We will explore this in detail further below.
There are different types of sequence input and output combination that can be applied across various applications.
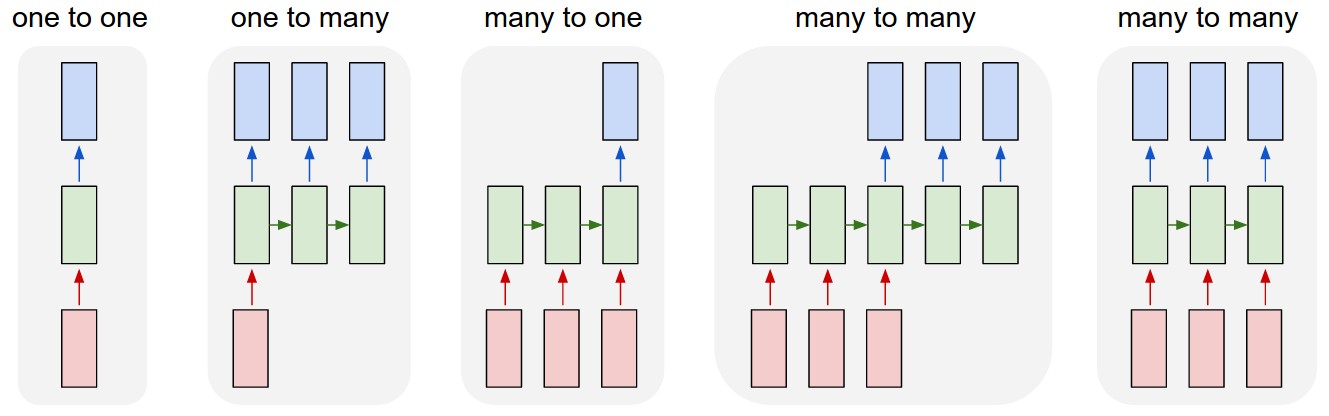
In above figure, inputs are green, output blue and RNN’s state in green. From left to right, One-to-One is what we saw in CNNs image classification where input image in, prediction output which class image belongs to i.e. fixed-size input to fixed-size output. One-to-Many contains sequence output, for fixed-input size, this can be task of image captioning where input is image and output is sentences of words. We know how multiple characters make up a word and multiple words combine to make a sentence. Many-to-one, here input is sequence and output is single prediction, which can be related to task of sentiment analysis, wherein input is sequence of words i.e. movie review and output is whether review is positive, neutral or negative. Next, Many-to-Many, here both input and output are sequence of words, which also happens in Machine Translation, where we input some sentence in English and get output sequence of words in French of varying length sequence. Another variant of Many-to-many, this can be related to video classification where we wish to label each frame in video.
We still haven’t answered what makes them special. Let’s deep dive and take apart RNN and assemble it to understand what makes RNNs special.
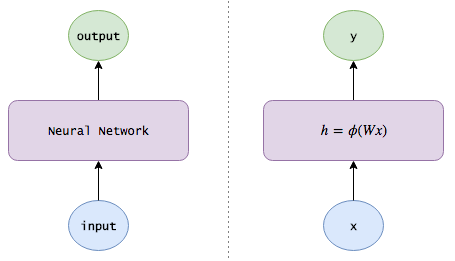
We have looked at how simple MLP works. We define, \(\mathbf{h}\) = \(\phi(\mathbf{W}\mathbf{x})\) , where \(\phi\) is an activation function and \(\mathbf{y}\) = \(\mathbf{V}\mathbf{h}\), where \(\mathbf{V}\) is weight matrix connecting hidden and output layers, \(\mathbf{W}\) weight matrix connecting input and hidden layer and \(\mathbf{x}\) is input vector. We also looked at different types of activation functions.
When we look at sequences of video frames, we use only the images as input to CNN and completely ignore sequential aspects present in the video. Taking example from Edwin Chen’s blog, if we see a scence of beach, we should boost beach activities in future frames: an image of someone in the water should probably be labeled swimming, not bathing, and an image of someone lying with their eyes closed is probably suntanning. If we remember that Bob just arrived at a supermarket, then even without any distinctive supermarket features, an image of Bob holding a slab of bacon should probably be categorized as shopping instead of cooking.
We need to integrate some kind of state which keeps tracks the current view of world for the model by continually updating as it learns new information. It sort of function like internal memory.
After modifying the above equation to incorporate some notion that our model keeps remembering bits of information, new equation looks like,
\[\begin{aligned} \mathbf{h}_{t} & = \phi(\mathbf{W}\mathbf{x}_{t} + \mathbf{U}\mathbf{h}_{t-1}) \\ \mathbf{y}_{t} & = \mathbf{V}\mathbf{h}_{t} \end{aligned}\]Here, \(\mathbf{h}_{t}\), hidden layer of network acts as internal memory storing useful information about input and passing the same info to next hidden layer so that it can update the state (internal memory or hidden layer) as new input comes. In this way, hidden layer sort of contains all this history of past inputs.
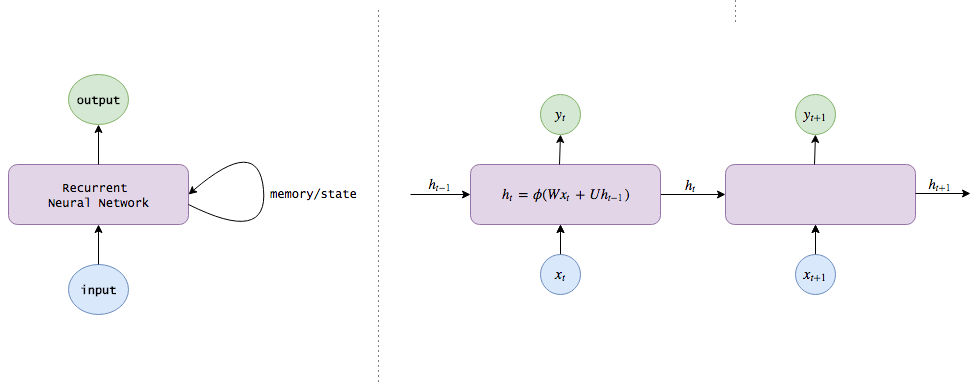
This is where the recurrent word comes into RNN, as we are using the same state(hidden layer) for every input again and again. Another way to think about how RNN works is, we get an input, our hidden layer captures some information about that input, and then when next input comes, the information in hidden layer gets updated according to new input but also keeping some of the previous inputs. So in all, hidden layer becomes an internal memory which captures information about what has been calculated so far. The below diagram shows unrolled RNN, if sequence contains 3 words, then the network will be unrolled into 3-layer network as shown below.
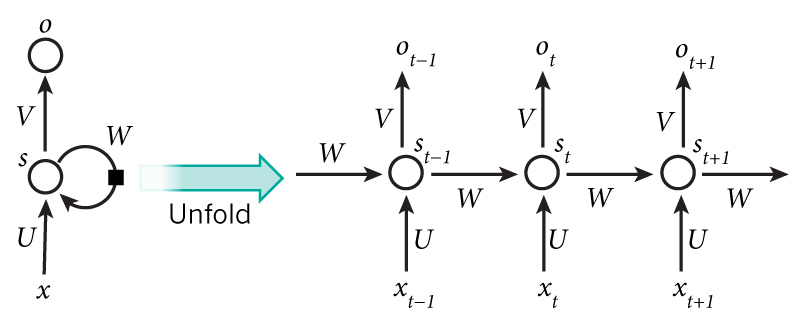
Here,
\(\mathbf{x}_{t}\) is input at time step t. It can be one-hot encoding of words or character or unique number associated with word or characters.
\(\mathbf{s}_{t}\) is hidden state at time step t. This is also called “state”, “internal memory(or memory)” or “hidden state” which is calculated as \(\mathbf{h}_{t}\) shown in the equations above. The nonlinearity usually used is ReLU or tanh.
\(\mathbf{o}_{t}\) is output state. We can apply softmax to get the probability across our vocabulary. All the outputs cannot be necessary for all tasks. For e.g., we may care only about last output for sentiment analysis, predict if it is positive, neutral or negative.
Here, we also note that the same parameters U, V, W are shared across all RNN layers(for all steps). This reduces a large number of parameters.
I-know-nothing: Yes Master, I concur (Dr.Frank Conners from Catch Me If You Can). But how is RNN trained and how does backpropagation work? Is the same as we looked in MLP?
I-know-everything: Now, onto the training and learning part of neural networks. We have seen in CNNs and MLPs, the usual process is to pass input, calculate the loss using predicted output and target output, backpropagate the error so as to adjust the weights to reduce the error, and perform these steps for millions of example (inputs, targets) pairs.
Training in RNNs is very similar to above. Also, the loss functions which we mentioned are the very ones used depending on different applications.
BPTT
Now, the backpropagation becomes BPTT i.e. jar jar backpropagation meets long time lost sibling jar jar backpropagation through time.
What BPTT means is that the error is propagated through recurrent connections back in time for a specific number of time steps. Within BPTT the error is back-propagated from the last to the first timestep, while unrolling all the timesteps. This allows calculating the error for each timestep, which allows updating the weights. BPTT can be computationally expensive when you have a high number of timesteps.
Let’s make this concrete with example.
Following above equations for RNN,
\[\begin{aligned} \mathbf{h}_{t} & = \phi(\mathbf{W}\mathbf{x}_{t} + \mathbf{U}\mathbf{h}_{t-1}) \\ \mathbf{\hat{y}}_{t} & = softmax(\mathbf{V}\mathbf{h}_{t})\\ \mathbf{E(\mathbf{y}, \mathbf{\hat{y}})} & = -\sum_{t}^{}\mathbf{y_{t}} \log{\mathbf{\hat{y}}_{t}} \end{aligned}\]Here, loss \(\mathbf{E(\mathbf{y}, \mathbf{\hat{y}})}\) is cross entopy loss. This can be stated as total error is summing error across all time steps. Training routine is, we pass in one word \(\mathbf{x}_{t}\) and get the predicted word at time t as \(\mathbf{\hat{y}}_{t}\) which is then used to calculate error at time step t along with actual word \(\mathbf{y}_{t}\). Total error can be obtained by summation of errors across all time steps t i.e. \(\mathbf{E(\mathbf{y}, \mathbf{\hat{y}})} = \sum_{t}^{}\mathbf{E_{t}(\mathbf{y}, \mathbf{\hat{y}})}\)
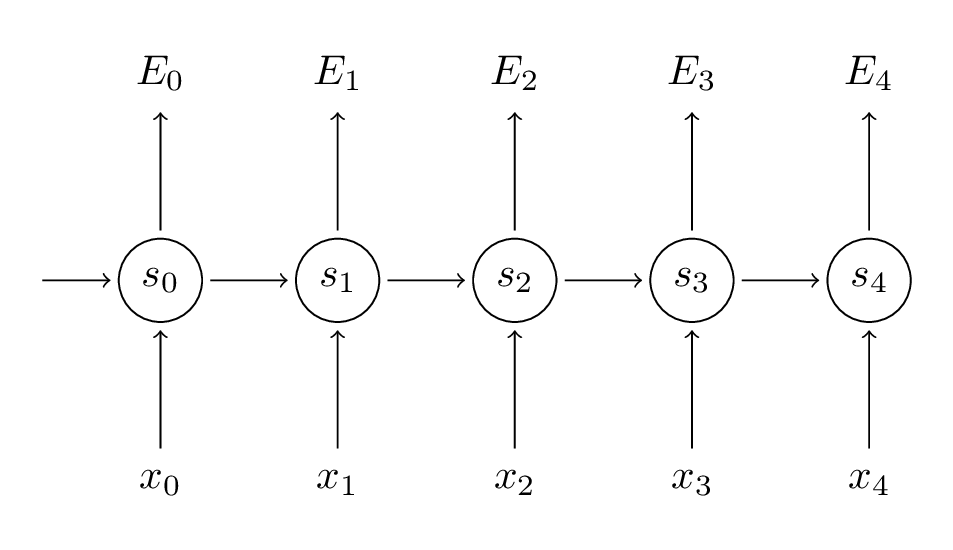
Now, we look at BPTT equations, the total gradient error \(\frac {\partial E}{\partial W} = \sum_{t}^{}\frac {\partial E_{t}}{\partial W}\) which is summation of individual gradient error across all time steps t just as done in calculating total error function.
If we calculate \(\frac {\partial E_{3}}{\partial W}\) (Why 3? we can further generalize to any number).
\[\begin{aligned} \frac {\partial E_{3}}{\partial W} = \frac {\partial E_{3}}{\partial \mathbf{\hat{y}}_{3}}\frac {\partial \mathbf{\hat{y}}_{3}}{\partial \mathbf{s}_3}\frac {\partial \mathbf{s}_3}{\partial W}\\ \mathbf{s}_{3} = tanh(\mathbf{U}\mathbf{x}_{t} + \mathbf{W}\mathbf{s}_{2}) \end{aligned}\]As we can see from above equation \(\mathbf{s}_{3}\) depends on \(\mathbf{s}_{2}\), and \(\mathbf{s}_{2}\) depends on \(\mathbf{s}_{1}\) and so on. Hence, we can further simply using chain rule and jump to writing \(\frac {\partial E_{3}}{\partial W}\) as,
\[\begin{aligned} \frac {\partial E_{3}}{\partial W} = \sum_{k=0}^{3}\frac {\partial E_{3}}{\partial \mathbf{\hat{y}}_{3}}\frac {\partial \mathbf{\hat{y}}_{3}}{\partial \mathbf{s}_3}\frac {\partial \mathbf{s}_3}{\partial \mathbf{s}_{k}}\frac {\partial \mathbf{s}_{k}}{\partial W} \end{aligned}\]
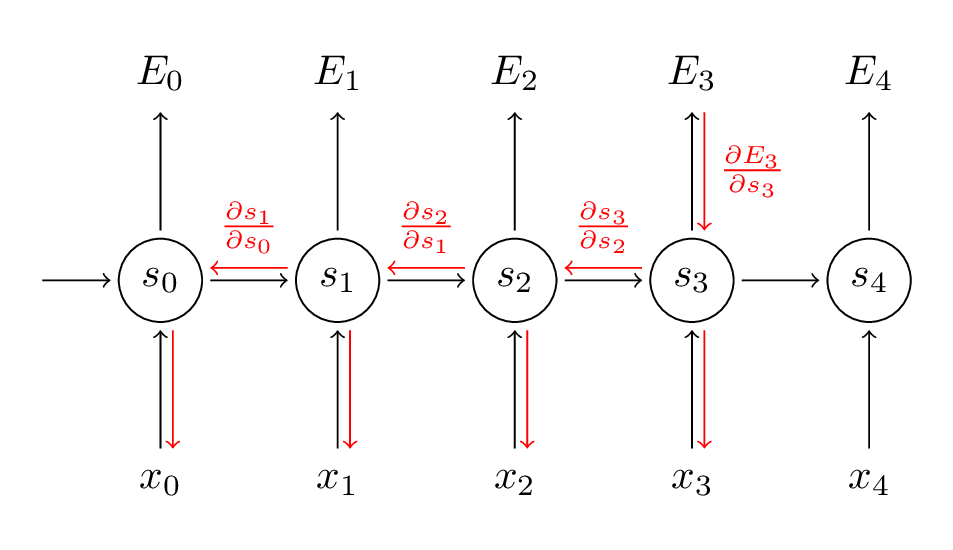
We sum up the contributions of each time step to the gradient. For example, to calculate the gradient \(\frac {\partial E_{3}}{\partial W}\) at t=3 we would need to backpropagate 3 steps (t = 0, 1, 2) and sum up the gradients(remember, zero-indexing).
This should also give you an idea of why standard RNNs are hard to train: Sequences (sentences) can be quite long, perhaps 20 words or more, and thus you need to back-propagate through many layers. In practice many people truncate the backpropagation to a few steps. Also, know as trauncated BPTT. Also, this accumulation of gradients from far steps leads to problem of exploding gradients and vanishing gradients explored in this paper.
To mitigate this problem of exploding gradients and vanishing gradients, we call in variants of RNN for help, which are LSTM and GRU. This will be topic of interest for our next post.
Character-Level Language Models
For now, we will look into char-rnn or Character RNN, where the network learns to predict next character. We’ll train RNN character-level language models. That is, we’ll give the RNN a huge chunk of text and ask it to model the probability distribution of the next character in the sequence given a sequence of previous characters. This will then allow us to generate new text one character at a time.
We will borrow example from Master Karpathy’s awesome blog,
If training sequence is “hello” then vocabulary i.e. unique characters in words (or text) are “h, e, l, o”, 4 letters.
We will feed one-hot encoded vector of each character one step at a time into RNN, and observe a sequence of 4-dimensional output vector as shown in diagram below.
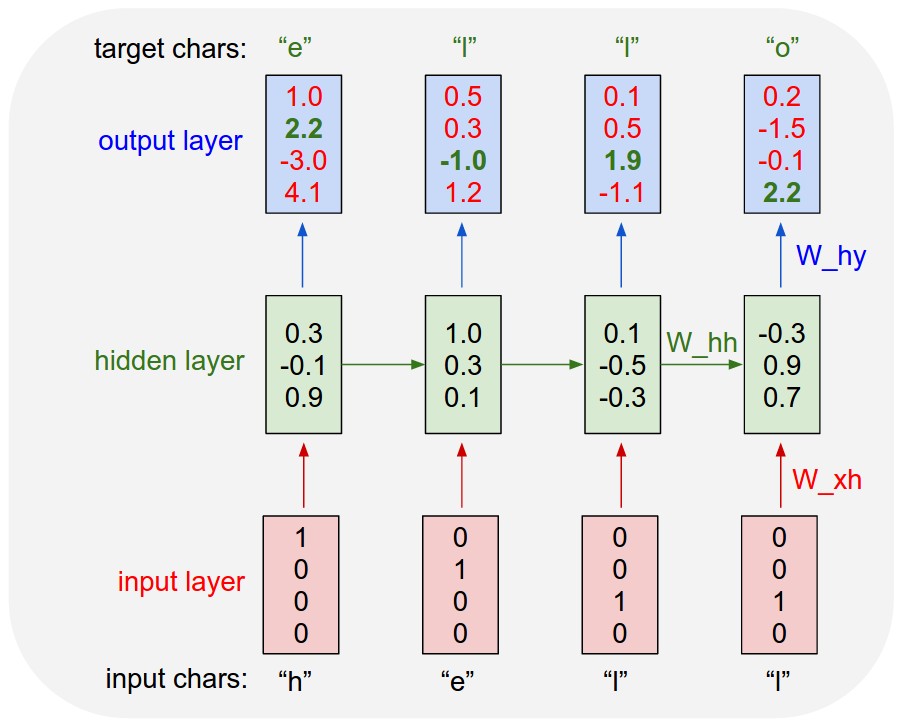
This diagram shows that input is “h”, “e”, “l”, “l” and we expect the predicted output to be “e”, “l”, “l”, “o”. The predicted output is shown in green color and we want it to be high as opposed to red ones.
I will let Master Karpathy to explain it more succinctly,
For example, we see that in the first time step when the RNN saw the character “h” it assigned confidence of 1.0 to the next letter being “h”, 2.2 to letter “e”, -3.0 to “l”, and 4.1 to “o”. Since in our training data (the string “hello”) the next correct character is “e”, we would like to increase its confidence (green) and decrease the confidence of all other letters (red). Similarly, we have a desired target character at every one of the 4 time steps that we’d like the network to assign a greater confidence to. Since the RNN consists entirely of differentiable operations we can run the backpropagation algorithm to figure out in what direction we should adjust every one of its weights to increase the scores of the correct targets (green bold numbers). We can then perform a parameter update, which nudges every weight a tiny amount in this gradient direction. If we were to feed the same inputs to the RNN after the parameter update we would find that the scores of the correct characters (e.g. “e” in the first time step) would be slightly higher (e.g. 2.3 instead of 2.2), and the scores of incorrect characters would be slightly lower. We then repeat this process over and over many times until the network converges and its predictions are eventually consistent with the training data in that correct characters are always predicted next.
Notice also that the first time the character “l” is input, the target is “l”, but the second time the target is “o”. The RNN therefore cannot rely on the input alone and must use its recurrent connection to keep track of the context to achieve this task. At test time, we feed a character into the RNN and get a distribution over what characters are likely to come next. We sample from this distribution, and feed it right back in to get the next letter.
There are different ways we can feed input data to RNN. Here is the outline of 2 such methods which can be used as input to RNN.
-
one-hot encoding inputs and one-hot encoding outputs
-
using the unique ids of input –> Embedding layer –> Output
We will talk about embedding layers in-depth in next post. Stay tuned!
This is how we train Character RNN. Now, let’s see what we played with.
Here are some of the results trained on text data of Shaskpeare, Nietzsche, Obama and Trump speeches and Tolstoy’s Anna Karenina.
ShakespeareRNN
To be or not to bell,
And made hus a polere of my hand.
CORIOLANUS:
I have be a there is shome to me,
Well sheep had stain and shanger of a morth.
SICINIUS:
The such one state a childry, wherefore.
MENENIUS:
O worthy hands,
The stroves of the son, time out to my stears on a man armon and wifold to hear hus that a stranges, who, the whare as he to me to he to me that tell thee,
To see this bands of theing of a shripts and whom his sonsering with a store as was a solfor our thee?
Second Servingman:
Which he shallst an hally the strieges of subres of the cause, and thy barther of the chombers, breath my brow to tell thee to me, and this dause this his some himself so men,
The secomair that a wenter's sides are as him as
this and to see it hat.
BRUTUS:
With the so farst wise high this freens,
But that with hapet heart the tales and have
The sone of make this sour are, this the man much anse
And which the partinious shall of a goneren sents,
Which the word wind they shall a place they dised
Is the didesters to make thy bast tongee
To see a souse, that I have stay and farther, thy lord,
Thou doth must courtest to he tas to be a man, and soul suck speach.
BUCKINGHAM:
Marry, my great strule, than a that of some at seting this true hard of the plint someting
That thou wast now shall the compreased to me.
To him of make of soul, we want to bear
Which to being tood a chorded thought an hants
And we discrack thee so the cried it seen,
And most thou should breat on and my steat of the cords.
KING RICHARD III:
Thy word,
Which thou day stand, stought they, sirst him them
As thin stend and still a stallow hearts
Our deviled on my love wort towe a man of thousand son that the were thou and the mean with a mate of a morrow.
KING RICHARD II:
Hade were is never be this thouser to the terme,
To the creater and the cause and fline
In sout to seed my states to be are true.
BRUTUS:
When, I what he,
What how and the poist a mendy,
And to her stint to take to that the mores, side they hath this sunce
NietzscheRNN
65. Wo lowe as all sere that the prost of the his oncation. Ane the
plessition of thisk of the perition of serecasing that at the porest of the calute a perisis to the sachite of this sears fart alo all trisg of a thish on is ancerting, and and
touth of--in this surablicising tion and
that in the concauly
of to sente them trigh to be a dentired of their have in the riscess, itself the sained and
mosters and as ont ofle the mort of the moderation of shaig ance tain this sears fict of that
ther in is alles and efont and
much is the resting or one
to
their incaine, and insucalie at of the sarn and thus a manting this sain for and inserites,
whe inselies itself, indorstanced. To all the conciest of
muralined which is incintly te ant intoring to and ast that the
pertert of such as astominated to be tree the sare imself camself in onlereds of cersingicare one ore penseste and surition ancestand
tomestite of a surition the man to that he priles in the rost as muntersto the miditing inderis and such of
the croutidic als
altound incerality it incertinct and the contions and to a the cand in the
sermictly itself in when
suppech the sain themety of to the reciare of that the comstarnce suct, and, at the montire, which inserest in the
carie to if it is it, and expiritains
and andincies, and atsing to as the couse that atered starious astemperstend and all the certe of
and to a caution to beem the pose oppirated to the superion a caulter the
poritation it to be a montes of the canter ont oncesenting and senigents to serfict to in which to be our is tratust of secianicy,
which the conses, as thought all astome himserfity of their that in a conce them as
a migher als the perposs itself, and
the consices of alsomantes," and ancouther
ther alsomen thay hay arouthing the complated--of that istent and must bat in thur in itself canster of meat ansomething tand to its of the regrationss, its to maty of heasty, and
ceness of this its sore a mart and aster it is not tore the sectulious
ObamaRNN
And the question I ask you to decide is to give you hope .
Now , amid the work of the United States of America -- between the United States and Australia -- i will never hesitate to use force or use military force to prevent attacks in America . But i have to let that happen again . Our military personnel and our troops have stopped our mission and a legitimate President ’s focus is on our efforts to put our military together .
And that 's why we need to use a military force , which is why i am increasing our troop presence in Vietnam for the first time since the Vietnam War . In other words , the situation in Vietnam has been fluid . The United States and Israel have been stronger than ever as we have served America ’s long - term security .
The United States and the United States continue to support our military efforts against military and diplomatic efforts . In America , we ’re partnering with NATO allies to strengthen our diplomatic relations , and we 're partnering with American diplomats to increase funding for American national security .
And we ’re encouraging regional support when Congress needs to demonstrate that the U.S. military is more efficient than our war effort . And that is why i have made it clear that America is not going to be dealing with foreign policy overnight .
So in eight years , Americans will continue to be a part of our American family . Over the last several years , we ’ve made a historic commitment to America ’s leadership in the 21st century .
In this era of an era where the status quo does n’t work , we ’ve begun a transition to a new America , and we continue to work with the American people to tackle the barriers that we 've been through so long as we pursue our shared goal : to revive our economy , to restore prosperity , to combat terrorism , to create jobs , to build new alliances , to increase build and restore future generations ; and to build a new foundation for lasting prosperity .
The last major economic crisis since the Great Depression found that the cost of energy , health care , and health care costs on both parties remains rising . That ’s why , over the weekend , i 'm proposing , on behalf of the American people -- what you 've been telling people what you are doing , how deeply we ’ll be able to make more than a million homes and how much money
TrumpRNN
Fake news conference ( WE ARE a FREE TRADE DEAL that WE LOVE IT , AND WE DON'T WIN . WE HAVE a VERY SMART MAN FOR THE COUNTRY THAT WE NEED AND WE NEED TO MAKE AMERICA SO GREAT AGAIN .
HE WAS GOING TO BE a FREE AND OPEN TRADE DEALS .
WE HAVE a CANDIDATE THAT WE HAVE TO BE STRONG TO MY FAMILY AND HERE IS HOW PUT IT TO US , GOING TO TAKE CARE OF THE PEOPLE , WE HAVE TO LOOK AT CHINA .
WE HAVE A LONG WAY TO DO IT . AND i HAVE TO BE THE PIGGY BANK THAT 'S ABOUT TRADE , YOU NEED THEM THAT i HAVE .
THAT HAS BEEN AND NOW WE HAVE THE GREATEST BUSINESSMEN IN THE WORLD AND THEY HAVE TO GO BACK AND TAKE OUR JOBS BACK , WE HAVE PROBLEMS WITH OUR PEOPLE THAT TAKE OUR JOBS .
WE HAVE a TINY FRACTION OF WHAT WE 'RE ABOUT AND i WAS IN . AND WE HAVE TO TAKE a LOOK AT WHAT WE WANT TO DO WITH OUR BUSINESS , WITH OUR COUNTRY .
WE HAVE TO GET IT BACK BEFORE , WE DON'T WANT THAT . WE HAVE a REAL THING ABOUT IT . WE'RE GOING TO MAKE GREAT DEALS AND NEGOTIATORS . WE HAVE TO GET PARTS OF THESE COUNTRIES .
WE HAVE a CLUE . TO HERE , WE SHOULD HAVE NEVER SEEN THE OTHER PEOPLE WHO WAS IN SMALL POTATOES . WE HAVE SOME OF THEM THAT THIS , WE HAVE TO BE GREAT AGAIN , FOLKS . WE'RE
AnnaRNN
Anna Arkadyevna Karenina _
Linking together a new trait in her master and her new nurse , Alexey
Alexandrovitch had been a French marquise , and had given food to her , and seemed to her a
propos de la femme la angel in the dim daylight of the theater .
She looked at him with a timid and guilty air , but at the same time she
was appalled at the fact that she was a distant part of his
regiment . He was more active in wrangling with him than anyone in the world ;
he saw that he never saw in his soul what he had been
thinking about . He felt that this was what he was thinking of himself . He must
find he responsible for everything , and had no special charm in him . But he had a feeling of love in
her soul , which had always hitherto been unbearable to her , and he felt that it was impossible to
take her in love . He felt that he was himself aware of the
force that filled her soul , and what he was doing , and she knew that in this matter she ought not to go to him .
The words and smiles seemed to him so alarming that he was reassured at once by the tenderness
of his soul . He raised
his head , looked at her , and whispered , " Thank
him ! " he moved away from him .
" Oh , yes , but when i 've been on your way , i 'll come to see me . " He was
delighted , and delighted to see Alexey Alexandrovitch at the
piano .
" Well , you have been a lamp and hope a great deal , " Alexey Alexandrovitch interrupted
him , and he smiled contemptuously .
" Oh , very well , and why did you announce Seryozha ? He
was telling him of the last ball , and the last ball , and everything
he wanted to say . He was a capital figure , but he felt
positively positively nervous . He 's not a fool , he 's a judge . He has grown up ; but now he 's
capable of amusing himself with it . "
" Well , how is it you never had anything to do with that ? i 've adopted it . Now do you know , i 'll come
round , " said Alexey Alexandrovitch . He did not even
agree with this . " Yes , it
Here are some other very interesting results, Cooking-Recipe, Obama-RNN, Bible-RNN, Folk-music, Learning Holiness, AI Weirdness, Auto-Generating Clickbait.
Be sure to look into “Visualizing the predictions and the “neuron” firings in the RNN” section of Master Karpathy’s blog to peek under the hood. We will do a seperate post the one similar to Visualizing CNN.
In next post, we explore the shortcomings of RNN by introducing Force of LSTM and GRU.
Happy Learning!
Note: Caveats on terminology
Force of RNN - Recurrent Neural Networks
loss function - cost, error or objective function
jar jar backpropagation - backpropagation
jar jar bptt - BPTT
BPTT - backpropagation through time
Further Reading
Must Read! The Unreasonable Effectiveness of Recurrent Neural Networks
Chater 9 Book: Speech and Language Processing by Jurafsky & Martin
Stanford CS231n Winter 2016 Chapter 10
Generating Text with Recurrent Neural Networks
Recurrent neural network based language model
A neural probabilistic language model
A Primer on Neural Network Modelsfor Natural Language Processing
Extensions of Recurrent neural network language model
Machine Learning for Sequential Data: A Review
On the difficulty of training recurrent neural networks
Footnotes and Credits
BPTT and Unrolled RNN
NOTE
Questions, comments, other feedback? E-mail the author