Adversarial Learning
In this post, we will see how one noisy image can break our state of the art deep learning algorithms.
All the codes implemented in Jupyter notebook in Keras, PyTorch and Tensorflow.
All codes can be run on Google Colab (link provided in notebook).
Hey yo, but how?
Well sit tight and buckle up. I will go through everything in-detail.

Feel free to jump anywhere,
Introduction to Adversarial Learning
A long time ago in a galaxy far, far away….

I-know-everything: My dear young padwan, you are learning quite a lot and honestly, keeping up with the pace of on-going reasearch in the field of deep learning, it’s really a challenge in itself. But we have tried to cover and focus on the basic concepts in Deep Learning and some applications. The journey so far has been like visting a lot of cool stations. We visited MLP, CNN, RNN, LSTM & GRU, and also we visited one the very famous places Transfer Learning in CNN and Transfer Learning in NLP. Hope you enjoyed the journey. A lot is still waiting to be explored. One such topic of interest today is about Adversarial Learning. But before that let me tell you a story about clever horse named Clever Hans who could do arithmetic.
I-know-nothing: Horse doing arithmetic? For real?
I-know-everything: Here is the picture of clever hans with its owner (from 1900s).

Clever Hans
There was a horse named Kluger Hans (clever hans) who could do arithmetic (Yes you read it right). The trainer of horse, Wilhelm von Osten, was not any kind of charlatan, didn’t want to make any money of any sort but gained a lot of attention and also believed it to be true. You could ask the horse to do 2+2 and then the horse would tap his foot 4 times. Huge crowd of people would gather and watch the horse perform. As far as anybody could tell, it really was able to actually answer wide variety of arithmetic questions people ask the horse. Later a psychologist decided to examine the horse. He went to an enclosed area with no other people and wore a mask and he asked the horse to do arithmetic and the horse couldn’t do it at all. It turned out what was happening that the horse had not learned arithmetic but horse had learned how to read people’s emotional reactions. So, you would ask the horse add 1 plus 2 and horse would tap his hoof once and crowd would stare at him in expectation. Then the horse would tap his hoof the second time and everybody in the crowd would sit on the edge and see, then he would tap his hoof the third time and everybody would be like oh my good he knows arithmetic. And then he would stop taping.
So, clever hans was trained to answer these questions. And he found a way of doing it that made him appear to be successful by metric of “Can he provide the right answer where roomful of people are watching him?” He hadn’t learned arithmetic and so could not generalise to unusual situations when there weren’t a room of people to provide the reactions that he needed to solve the problem.
I-know-nothing: Ahh now I see, the horse indeed was clever in reading people’s emotional reactions. But how does this relate to Machine Learning I wonder?
I-know-everything: Great! So, we have seen how a vision model, where we use CNN, was able to attain human level accuracy in classifying images and we also saw what the model is actually looking at when it is classifying the image. If we give the following image of “panda” to the classifier it correctly predicts that image as “panda” but if we add a little(calculated and not random) noise to the same image, as you can see the resultant image(original image + noise) isn’t much different from the original panda image. If we pass this resultant image to the classifier, it predicts the image as “gibbon” with 99% confidence.(😞) This resultant image is called “Adversarial Example”. This example is fooling CNN into thinking that panda is a gibbon.
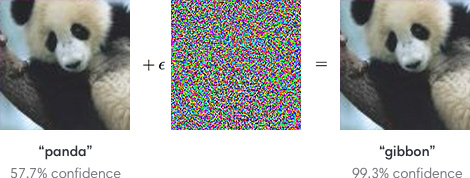
An Adversarial Example is an example that has been carefully computed to be misclassified. To make a new image indistinguishable to human obeserver from original image. Adversaries can craftily manipulate legitimate inputs, which may be imperceptible to human eye, but can force a trained model to produce incorrect outputs.
I-know-nothing: So what is really going on? Did the classifier cheat with us the same way Clever hans did? Are there any other methods which we can cheat? Is there any way to defend this cheating? Is it only in images or also in other tasks such as NLP and RL? This cheating can really put the state of the art classifier in a very difficult position as to Are they really state of the art(SOTA) in classification? What if someone misuses these techniques of fooling the classifier, this certainly has some serious after effects.
I-know-everything: That is certainly true. This issue of adversarial example does put the mark on SOTA classifier really in a jeopardy! Are they really good as they claim, beating humans?
There are mainly 3 types of adversarial attacks. We will explain why is it so easy to perform them, and discuss the security implications that stem from these attacks.
- Gradient-based adversarial attack
- Optimization-based adversarial attack
- Model stealing techniques
Adversarial Attacks
A trained CNN model acts as a linear seperator for high dimensional data for different classes, where every point(image) is associated with its class. Of course, the boundary of seperation is not perfect. This provides an opportunity to push one image from one class to another (cross the boundary) i.e. perturbing the input data in the direction of another class.
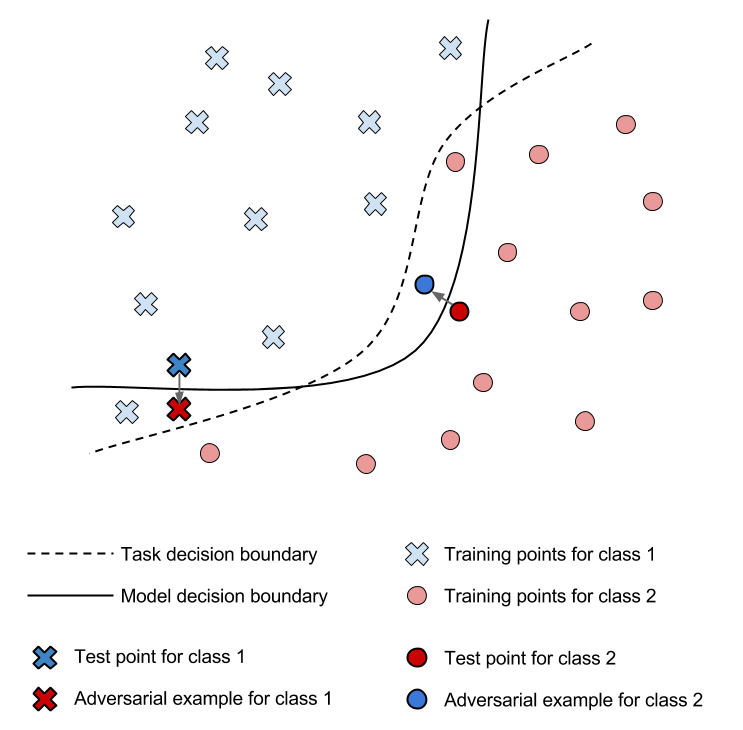
A better way to illustrate the two, non-targeted and targeted attack is explained by the story of Sherlock Holmes on cleverhans blog :
Suppose Professor Moriarty wishes to frame Sherlock Holmes for a crime. He may arrange for an unsuspected accomplice to give Sherlock Holmes a pair of very unique and ornate boots. After Sherlock has worn these boots in the presence of the policemen he routinely assists, the policemen will learn to associate the unique boots with him. Professor Moriarty may then commit a crime while wearing a second copy of the same pair of boots, leaving behind tracks that will cause Holmes to fall under suspicion.
In machine learning, the strategy followed by the adversary is to perturb training points in a way that increases the prediction error of the machine learning when it is used in production. The simplest yet still very efficient algorithm is known as Fast Gradient Step Method (FGSM) is used by both the attacks to generate adversarial examples(very fast) introduced in this paper by Goodfellow and colleagues at Google. The core idea is to add some defined \(\epsilon\) weak noise on every step of optimization, drifting towards the desired class (targeted) — or, away from the correct one (non-targeted).
\[\begin{aligned} x^{adv} & = x + \epsilon * sign(\nabla_{x} J(x, y_{true})) \\ \textbf{where}, x &= \textbf{clean image} \\ x^{adv} &= \textbf{perturbed adversarial image} \\ J &= \textbf{classification loss} \\ y_{true} &= \textbf{true label for input image x} \\ \end{aligned}\]Gradient-based adversarial attack
These are the simplest technique that demonstrate the linearity of neural networks using Fast-Gradient Sign Method(FGSM) and as the name suggest they make use of gradients for successful attacks.
Non-targeted adversarial attack
Non-targeted adversarial attack uses FGSM to makes the classifier to give incorrect result of any other class than input image class. Here the objective is to perturb the input image in direction where the gradient increases error by some \(\epsilon\) in such a way that when we reconstruct the resultant adversarial image it looks indistinguishable than the original image.
def non_targeted_attack(img):
img = img.cuda()
label = torch.zeros(1, 1).cuda()
x, y = Variable(img, requires_grad=True), Variable(label)
for step in range(steps):
zero_gradients(x)
out = model(x)
y.data = out.data.max(1)[1]
_loss = loss(out, y)
_loss.backward()
normed_grad = step_alpha * torch.sign(x.grad.data)
step_adv = x.data + normed_grad
adv = step_adv - img
adv = torch.clamp(adv, -eps, eps)
result = img + adv
result = torch.clamp(result, 0.0, 1.0)
x.data = result
return result.cpu(), adv.cpu()

Targeted adversarial attack
Targeted adversarial attack uses FGSM to makes the classifier to give incorrect result of specific class for given input image. The main change is the sign of the gradient. As opposed to the non-targeted attack, where the goal was to increase the error assuming that the targeted model is almost always correct, here we are going to minimize the error. Here we minimize the error by computing loss with respect to given (incorrect target) label such that when attack completes, the image outputs that it belongs to the specific class, making the attack successful.
def targeted_attack(img, label_idx):
img = img.cuda()
label = torch.Tensor([label_idx]).long().cuda()
x, y = Variable(img, requires_grad=True), Variable(label)
for step in range(steps):
zero_gradients(x)
out = model(x)
_loss = loss(out, y)
_loss.backward()
normed_grad = step_alpha * torch.sign(x.grad.data)
step_adv = x.data - normed_grad
adv = step_adv - img
adv = torch.clamp(adv, -eps, eps)
result = img + adv
result = torch.clamp(result, 0.0, 1.0)
x.data = result
return result.cpu(), adv.cpu()

Here is one example by Goodfellow et al in using 2d Adversarial Objects in fooling neural networks,

Here is one example from lab six where they use 3d Adversarial Objects in fooling neural networks,

These are not only the gradient-based adversarial attacks but are the simplest.
Optimization-based adversarial attack
C&W attack introduced in Towards Evaluating the Robustnessof Neural Networks is by far one of the strongest attacks. They formulate targeted adversarial attacks as an optimization problem, take advantage of the internal configurations of a targeted DNN for attack guidance, and use the \(L_{2}\) norm (i.e. Euclidean distance) to quantify the difference between the adversarial and the original examples. In particular, the representation in the logit layer (the layer prior to the final fully connected layer) is used as an indicator of attack effectiveness. Consequently, the C&W attack can be viewed as a gradient-descent based targeted adversarial attack driven by the representation of the logit layer of a targeted DNN and the \(L_{2}\) distortion. C&W attack picks random multiple random starting points close to the original image and run gradient descent from each of those points for a fixed number of iterations. They tried three optimizers — standard gradient descent, gradient descent with momentum, and Adam — and all three produced identical-quality solutions. However, Adam converges substantially more quickly than the others.
Model stealing techniques
Model stealing Techniques are used to “steal” (i.e., duplicate) models or recover training data membership via blackbox probing. Both the above attacks can be considered as whitebox attacks where the attacker has access to the model’s parameters (gradient in this case) whereas in black box attacks, the attacker has no access to these parameters, i.e., it uses a different model or no model at all to generate adversarial images with the hope that these will transfer to the target model.
In the black-box settings, the machine learning model is said to act as an oracle. One strategy in using black-box setting for stealing called oracle attack is to first query the oracle in order to extract an approximation of its decision boundaries—the substitute model—and then use that extracted model to craft adversarial examples that are misclassified by the oracle. This is one of the attacks that exploit the transferability of adversarial examples: they are often misclassified simultaneously across different models solving the same machine learning task, despite the fact that these models differ in their architecture or training data.
Here is one example from lab six where they use Partial Information Attacks on Real-world AI another black-box attack,
Sometimes perturbing too many pixels can make the modified image seem perceptible to human eye. Su et al proposed a method by perturbing only one pixel with differential evolution using black-box setting.
![]()
Changing one pixel turns ship into 99.7% car, horse into 99.9% frog or a deer into airplane. This means we cannot just randomly select any pixel from image, it has to be specific for it to work. This is where Differential Evolution comes into play. DE belongs to the general class of evolutionary algorithms which does not use the gradient information for optimizing and therefore do not require the objective function to be differentiable. As with typical EA algorithms during each iteration, set of candidate solutions is generated according to current population. Then children are compared with their corresponding parent surviving if they are more fitted than their parents. The last surviving child is used to alter the pixel in the image. And this is how from random pixels DE chooses one pixel which confidently changes the class to input image.
Real World Examples
- Print a “noisy” ATM check written for $100 – and cash it for $1,000,000.
- Swap a road sign with a slightly perturbed one that would set the speed limit to 200 – in a world of self-driving cars it can be quite dangerous.
- Don’t wait for self-driving cars – redraw your license plate and cameras will never recognise your car.
- Cause an NSFW detector to incorrectly recognise an image as safe-for-work
- Cause an ad-blocker to incorrectly identify an advertisement as natural content
- Cause a digital assistant to incorrectly recognize commands it is given
- Cause a malware (or spam) classifier to identify a malicious file (or spam email) as benign

Here is a recent demo by Tencent Keen Security Lab which conducted research on Autopilot of Tesla Model S and achieved 3 flaws, Auto-wipers Vision Recognition Flaw, Lane Recognition Flaw and Control Steering System with Gamepad. For more details on the technical details, here is the paper and must watch video demonstrating each of the flaws. Controlling Tesla steering with Gamepad, finally all GTA practise paying off.
And imagination is limit. There are so many bad examples which can be exploited. Just like any new technology not designed with security in mind, when deploying a machine learning system in the real-world, there will be adversaries who wish to cause harm as long as there exist incentives(i.e., they benefit from the system misbehaving).
Defenses against Adversarial Attacks
What can be done? How can we avoid Adversarial attacks? From criticality of above real-world examples we can infer that Adversarial Examples are security concern. Thus there is need to create a robust machine learning algorithm such that if a powerful adversary who is intentionally trying to cause a system to misbehave cannot succeed. Adversarial training can defend against FGSM attack by causing gradient masking, where locally the gradient around a given image may point in a direction that is not useful for generating an adversarial example.
One way for Adversarial training is to proactively generate adversarial examples as part of the training procedure. We have already seen how we can leverage FGSM to generate adversarial examples inexpensively in large batches. The model is then trained to assign the same label to the adversarial example as to the original example—for example, we might take a picture of a cat, and adversarially perturb it to fool the model into thinking it is a vulture, then tell the model it should learn that this picture is still a cat. Adversarial training is a standard brute force approach where the defender simply generates a lot of adversarial examples and augments these perturbed data while training the targeted model. Adversarial training of a model is useful only on adversarial examples which are crafted on the original model. The defense is not robust for black-box attacks where an adversary generates malicious examples on a locally trained substitute model.
Another way is gradient hiding which consists of hiding information about model’s gradient from adversary by using non-differentiable models such as a Decision Tree, a NearestNeighbor Classifier, or a Random Forest. However, this defense are easily fooled by learning a surrogate Black-Box model having gradient and crafting examples using it. The attacker can train their own model, a smooth model that has a gradient, make adversarial examples for their model, and then deploy those adversarial examples against our non-smooth model.
There are many different defenses such as Defensive Distillation, image processing methods such as scalar quantization, spatial smoothing filter, squeezing color bits and local/non-local spatial smoothing and many more where each is good against specific attacks.
Evaluating Adversarial Robustness
The competition between attacks and defenses for adversarial examples becomes an “arms race”: a defensive method that was proposed to prevent existing attacks was later shown to be vulnerable to some new attacks, and vice versa. Some defenses showed that they could defend a particular attack, but later failed with a slight change of the attack. Hence, the evaluation on the robustness of a deep neural network is necessary. Nicholas Carlini et al in On Evaluating Adversarial Robustness outlines three common reasons why one might be interested in evaluating the robustness of a machine learning model which are, To defend against an adversary who will attack the system, to test the worst-case robustness of machine learning algorithms and to measure progress of machine learning algorithms towards human-level abilities. Adversarial robustness is a measure of progress in machine learning that is orthogonal to performance.
Beyond Images
Adversarial examples are not limited to image classification. Adversarial examples are seen in speech recognition, question answering systems, reinforcement learning, object detection and semantic segmentation and other tasks.
Speech Recognition

Question Answering Systems

RL

Object Detection and Semantic Segmentation


Conclusion
- The study of adversarial examples is exciting because many of the most important problems remain open, both in terms of theory and in terms of applications.
- On the theoretical side, no one yet knows whether defending against adversarial examples is a theoretically hopeless endeavour (like trying to find a universal machine learning algorithm) or if an optimal strategy would give the defender the upper ground (like in cryptography and differential privacy). The lacking of proper theoretical tools to describe the solution to these complex optimization problems make it even harder to make any theoretical argument that a particular defense will rule out a set of adversarial examples.
- On the applied side, no one has yet designed a truly powerful defense algorithm that can resist a wide variety of adversarial example attack algorithms. Most of the current defense strategies are not adaptive to all types of adversarial attack as one method may block one kind of attack but leaves another vulnerability open to an attacker who knows the underlying defense mechanism.
Well that concludes adversarial machine learning. Where to next? Power of GAN.
Happy Learning!
Note: Caveats on terminology
FGSM - Fast Gradient Sign Method
C&W - Carlini and Wagner
CNN - Convolution Neural Networks
RL - Reinforcement Learning
GAN - Generative Adversarial Networks
Further Reading
Stanford CS231n 2017 Lecture 16 Adversarial Examples and Adversarial Training
Nicholas Carlini’s Adversarial Machine Learning Reading List
Explaining and Harnessing Adversarial Examples
Adversarial Examples Are Not Easily Detected: Bypassing Ten Detection Methods
Adversarial Examples in Real Physical World
Adversarial Examples: Attacks and Defenses for Deep Learning
Adversarial Examples for Evaluating Reading Comprehension Systems
On Evaluating Adversarial Robustness
Towards Evaluating the Robustness of Neural Networks
Synthesizing Robust Adversarial Examples
Towards Deep Learning Models Resistant to Adversarial Attacks
The limitations of adversarial training and the blind-spot attack
The Limitations of Deep Learningin Adversarial Settings
One Pixel Attack for Fooling Deep Neural Networks
Black-box Adversarial Attacks with Limited Queries and Information
Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning
CAMOU: Learning a Vehicle camouflage for physical adversarial attack on object detectors in the wild
Practical Black-Box Attacks against Machine Learning
Are Adversarial Examples Inevitable?
Towards the first adversarially robust neural network model on MNIST
Adversarial Attacks and Defences: A Survey
Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey
Adversarial Attacks on Deep Learning Models in Natural Language Processing: A Survey
cleverhans blog: Breaking things is easy, Is attacking machine learning easier than defending it? and The challenge of verification and testing of machine learning
Gradient Science’s blog: A Brief Introduction to Adversarial Examples, Training Robust Classifiers (Part 1) and Training Robust Classifiers (Part 2)
Elie’s blog on Attacks against machine learning — an overview
Safety and Trustworthiness of Deep Neural Networks: A Survey
Adversarial learning literature
Footnotes and Credits
NOTE
Questions, comments, other feedback? E-mail the author